| ПОЗНАВАТЕЛЬНОЕ Сила воли ведет к действию, а позитивные действия формируют позитивное отношение Как определить диапазон голоса - ваш вокал Игровые автоматы с быстрым выводом Как самому избавиться от обидчивости Противоречивые взгляды на качества, присущие мужчинам Вкуснейший "Салат из свеклы с чесноком" Натюрморт и его изобразительные возможности Применение, как принимать мумие? Мумие для волос, лица, при переломах, при кровотечении и т.д. Как научиться брать на себя ответственность Зачем нужны границы в отношениях с детьми? Световозвращающие элементы на детской одежде Как победить свой возраст? Восемь уникальных способов, которые помогут достичь долголетия Классификация ожирения по ИМТ (ВОЗ) Глава 3. Завет мужчины с женщиной
Оси и плоскости тела человека - Тело человека состоит из определенных топографических частей и участков, в которых расположены органы, мышцы, сосуды, нервы и т.д.
| Древовидные и решетчатые диаграммы. 12
Для большей наглядности таблицу 2 можно отобразить диаграммой рис. 7. Построение диаграммы начинаем с точки если на вход кодера первым информационным символом будет подана единица (1), то через точку если бы первым информационным символом был 0, то этот вертикальный отрезок направили бы вверх от точки Так как первый информационный символ, подаваемый на вход, есть 1, то вертикальный отрезок, проходящий через точку
Рис. 7 Диаграмма выходных символов (ими обозначены горизонтальные отрезки), как реакция кодера на входные символы (ими обозначены вертикальные отрезки).
Так как второй информационный символ, поступающий на вход снова - есть 1, то, согласно правилу, из конца первого горизонтального отрезка проводим вертикальный отрезок, направленный снова вниз. Поступивший на вход кодера второй информационный символ согласно таблице 2 является причиной появления на выходе кодера последовательности 01 и поэтому горизонтальный отрезок, проведенный из конца второго вертикального отрезка, обозначаем как 01 и т.д. Начиная с 4-го символа, на вход подаются нулевые символы, и поэтому вертикальные отрезки, соответствующие этим символам, направляем вверх. В результате получаем всю диаграмму, изображенную на рис. 7. Если, вместо взятой в данном примере входной последовательности информационных символов, на вход кодера подадим другую последовательность, то таблица заполнится другими символами, и им будет соответствовать другая диаграмма. Всевозможные диаграммы можно объединить в одну общую диаграмму (рис. 8), которую назовем древовидной диаграммой для сверточного кода, а исходные диаграммы будут являться ветвями этого дерева. Так диаграмме, изображенной на рис. 7 , на общей древовидной диаграмме рис. 8 соответствует ветвь, обозначенная пунктиром. Т.е., если на вход кодера поступают информационные символы 111000, то на выходе кодера получаем: 11 01 10 01 11 00. Еще раз напомним, что при построении диаграммы рис. 8 и таблицы 2 предполагается, что первоначально ячейки регистра сдвига содержали одни нули. На рис. 8 видно, что древовидная диаграмма состоит из узлов и ребер. Узлы – это точки, которые обозначены буквами: Появление любой из этих комбинаций на выходе кодера зависит от состояния кодера, т.е. от того, из какого узла В дальнейшем, чтобы исключить возможную путаницу будем всегда понимать под состояниемкодера содержание второй и третьей ячеек после подачи информационного символа. В общем случае, когда кодовое ограничение Итак, состояния кодера (рис. 1) могут принимать следующие значения: 00,10,01 или 11 и эти состояния соответствуют узлам Из древовидной диаграммы видно, что при росте длины входной информационной последовательности число узлов на дереве растет как
Рис. 8 Древовидное представление кодера рис. 1. ром В 1967 году Д.Форни удалось преодолеть этот недостаток. Он обратил внимание на то, что ребра, выходящие из любых двух вершин древовидной диаграммы, которым соответствуют одинаковые состояния (например, состояние
Рис. 9 Решетчатая диаграмма кодера.
Все узлы решетки, расположенные вдоль верхней горизонтали имеют одно и тоже состояние При построении решетки, как и при построении древовидной диаграммы (рис. 8) предполагается, что первоначально ячейки регистра сдвига кодера содержали одни нули, т.е. вначале кодер находится в состоянии Если на вход кодера, находящегося в состоянии На решетчатой диаграмме для усиления различия откликов на 0 и 1, ребра, обозначающие эти отклики, будем изображать сплошной линией и пунктирной линией соответственно. Таким образом, на уровне 0 обе диаграммы (древовидная и решетчатая) в качественном отношении полностью соответствуют друг другу. Это соответствие также проявляется и для 1-го и 2-го уровней. На обеих диаграммах на 1-ом уровне имеется два узла Различие между диаграммами, начиная с 3-го уровня, носит принципиальный характер. На древовидной диаграмме на 3-ем уровне расположено 8-м узлов: два узла « Два узла « На 4-м уровне на древовидной диаграмме отождествляются четыре узла « В отличие от древовидной диаграммы в результате описанных отождествлений получается решетчатая диаграмма, на которой на любом уровне после 3-го имеется всего 4-е узла. В общем случае (при любом По заданной последовательности входных информационных символов (ИС) с помощью решетчатой диаграммы и по древовидной диаграмме легко определить последовательность кодовых символов (ПКС) на выходе кодера. Так, например, для последовательности 111000 входных символов с помощью решетчатой диаграммы на основе использования изложенных выше правил движения по решетке, получаем кодовую последовательность 11 01 10 01 11 00 , которая, естественно, совпадает с кодовой последовательностью, полученной по древовидной диаграмме. Данной кодовой последовательности на решетчатой диаграмме соответствует путь, обозначенный точками (рис 9). Этот путь получается следующим образом. Движение по решетке начинаем с расположенного слева узла С помощью решетчатой диаграммы по заданной ПКС нетрудно определить также ИС, которые явились причиной появления заданных кодовых символов. Так, если кодовая последовательность имеет вид 11 01 10 01 11 00, то соответствующей информационной последовательностью будет 111000. В этом случае соответствие между кодовыми и информационными символами устанавливаем по диаграмме, начиная с левого узла Из узла В 1967 г. Д.Форни обосновал применение решетчатых диаграмм, в том же году другой американский ученый А.Д.Витерби предложил новый метод декодирования сверточных кодов, основанный на использовании решетчатых диаграмм в виде достаточно простой итеративной процедуры, которая получила название «алгоритм Витерби» и успешно применяется на практике и в настоящее время. Цель декодирования в случае использования сверточных кодов такая же, как и при использовании блочных кодов – исправить возможные ошибки при приеме кодовых символов, которые могут возникнуть на выходе демодулятора. Поэтому возникает вопрос о количестве исправляемых ошибок. Сколько ошибок может быть исправлено при декодировании свёрточного кода? В случае блочного кода имелось в виду количество ошибок, которые могут произойти в пределах одной кодовой последовательности (одного блока), поэтому количество исправляемых ошибок определялось целым числом В случае сверточного кодирования нет блоков, поэтому необходимо: 1) ввести какую-то единицу длины, эквивалентную длине блока. При постановке вопроса о количестве исправляемых ошибок сверточным кодом нужно иметь в виду количество ошибок в пределах этой единицы длины; 2) определить для сверточных кодов такой важный параметр, как кодовое расстояние Исследования сверточных кодов показали: если интервал между ошибками составляет если же интервал между двумя соседними ошибками меньше, чем Таким образом, в случае сверточных кодов интервал протяженностью Напомним, что кодовое расстояние Это свойство кодового расстояния для блочных кодов можно распространить и на сверточные коды. Кодовое расстояние Эта последовательность ранее была получена и была названа « импульсной характеристикой сверточного кодера » (рис. 5). Можно найти отклик кодера на указанную последовательность 1000… также с помощью решетчатой диаграммы. Это будет та же самая последовательность 11 10 11 00 00…Расстояние Хемминга между этой кодовой последовательностью и нулевой кодовой последовательностью равна 5, т.е. кодовое расстояние для сверточного кода, порождаемым кодером на рис. 1 , будет равно Для блочных кодов количество исправляемых ошибок
Таким образом, если В случае сверточных кодов вместо параметра
АЛГОРИТМ СВЕРТОЧНОГО ДЕКОДИРОВАНИЯ ВИТЕРБИ.
С целью реализации устойчивой работы кодера при сверточном декодировании периодически проводят очистку (промывку) регистра сдвига кодера от информационных символов путем подачи на кодер некоторого количества нулевых символов (не информационных). Эта операция называется периодическим отбрасыванием. Следующая партияинформационных символов поступает на кодер, когда все ячейки регистра сдвига находятся в нулевом состоянии, т.е. в состоянии 1) 2) 3) С учетом сказанного рассмотрим алгоритм сверточного декодирования Витерби с использованием решетчатой диаграммы. Декодирование начинается в момент Предположим, что входная последовательность ИС на входе кодера
от кодера по каналу связи передавалась кодовая последовательность (КП)
состоящая из одних нулевых символов (можно было бы в качестве примера выбрать любую другую КП, но за последовательностью, состоящую из одних нулей, проще проследить по решетчатой диаграмме). Далее предположим, что в результате ошибок в демодуляторе на вход декодера вместо передаваемой кодовой последовательности (КП) (10) поступила последовательность (т.е. ошибки произошли в тех разрядах, где стоят единицы). На основании вышесказанного следует, расстояние между единицами в КП На рис. 10 изображена решетчатая диаграмма декодера.
Рис. 10 Решетчатая диаграмма декодера ( степень кодирования Решетчатая диаграмма декодера на рис. 10 отличается от решетчатой диаграммы кодера на рис. 9 тем, что ребрам этих решеток соответствуют разные обозначения. Числа над ребрами решетки декодера определяются, как расстояния Хемминга между двумя символами принятой последовательности Теперь изобразим отдельно ту часть решетчатой диаграммы декодера, которая расположена между моментами
Рис. 11 Решетчатая диаграмма декодера между моментами Определим по диаграмме на рис. 11 метрику путей по Хеммингу, исходящих из одной точки
В узел
В узел
В узел
Целью алгоритма Витерби является то, что из двух путей, приходящих в каждый из узлов Снова построим диаграмму, но на ней укажем только выжившие пути к моменту
Рис. 12 Выжившие пути к моменту Теперь полученную диаграмму на рис. 12 достроим соответствующими ребрами до момента
Рис. 13 Выжившие пути к моменту Над вновь достроенными ребрами (рис. 13) указываем расстояния Хемминга между двумя символами принятой последовательности
В узел
В узел
В узел
Аналогично вышесказанному из двух путей, приходящих в узел
Рис. 14 Выжившие пути к моменту Достраиваем полученную диаграмму соответствующими ребрами до момента
Согласно вышесказанному выживают такие пути:
Рис. 15 Выжившие пути к моменту Снова достраиваем полученную диаграмму соответствующими ребрами до момента
Выживают пути: Построим на диаграмме эти пути (рис. 16).
Рис. 16 Выжившие пути к моменту Снова достраиваем полученную диаграмму соответствующими ребрами до момента
Выживают пути: строим на диаграмме декодера эти пути (рис.17):
Рис. 17 Выжившие пути на решетчатой диаграмме декодера к моменту Из построенной на рис. 17 диаграммы декодера видно, что от момента 00 00 00 00 00:
Рис. 18 Выживший путь Декодер принимает решение, что на интервале от
Из рассмотренного примера можно сделать следующие выводы: 1) При декодировании используются как решетчатая диаграмма кодера, так и решетчатая диаграмма декодера. Когда из демодулятора поступает пара принятых символов между моментами времени Из сказанного следует, что решетчатая диаграмма кодера всегда одна и та же (она не зависит от принятой последовательности), а решетчатая диаграмма декодера определяется как диаграммой кодера, так и принятой последовательностью 2) С помощью пометок (цифр) на ребрах решетчатой диаграммы декодера для момента времени Декодирование Витерби состоит в том, что из двух путей, приходящих в один узел, при продолжении операции декодирования выживает только один – тот, которому соответствует меньшее расстояние Хемминга. Если эти два расстояния имеют одинаковую величину, то произвольно выбирается любой из двух. Отсекание одного из двух путей, сходящихся в узле решетки, гарантирует, что число продолжающихся путей будет равно числу состояний (т.е. четырем для рассматриваемого кодера). В этом заключается существенное преимущество решетчатой диаграммы при сравнении с древовидной диаграммой при декодировании. Как отмечалось выше, при использовании древовидной диаграммы число возможных путей растет очень быстро – по закону В результате использования алгоритма декодирования Витерби находится наиболее вероятный (с минимальным расстоянием Хемминга) путь через решетку декодера. При определении этого пути происходит исправление ошибок, возникших при приеме передаваемой кодовой последовательности. Как уже отмечалось, количество ошибок Эту же величину Параметр Предполагается, что по каналу передавалась нулевая последовательность
и принятая последовательность
Для этой нулевой последовательности На диаграмме декодера (рис. 19) строятся всевозможные пути, которые расходятся из нулевого пути и снова возвращаются на нулевой путь в каком-то узле.
Рис. 19 Решетчатая диаграмма декодера последовательности На рис 20 построены три пути, расходящиеся из нулевого пути в точке
Рис. 20 Решетчатая диаграмма декодера последовательности от момента Из диаграммы рис. 20 можно определить метрику этих путей по Хеммингу:
На рис. 20 можно построить и другие аналогичные пути, но им будут соответствовать метрики большей величины. Минимальная величина из метрик таких путей называется минимальным просветом (или просто просветом) и обозначается Таким образом, для рассматриваемого свёрточного кода (степень кодирования равна Рассмотрим еще один случай исправления комбинаций ошибок, характерный для ОФМ, когда две ошибки следуют друг за другом. Пусть
Как отмечено выше в последовательности (15) ошибкам соответствуют единичные символы. Пользуясь методикой построения решетчатых диаграмм предыдущего примера, строим диаграммы декодера рис. 21-рис. 29.
Рис. 21 Диаграмма декодера последовательности
Рис. 22 Выжившие пути к моменту
Выжившие пути на рис. 22 и рис. 23, а также на рис. 24
Рис. 24 Выжившие пути к моменту достроенные до момента
Рис. 25 Выжившие пути к моменту
Рис. 27 Выжившие пути к моменту
Рис. 28 Выжившие пути к моменту
Строим на рис. 29 те пути, которые отмечены знаком 1. Для момента 2. Если для момента
Рис. 29 Выживший путь от момента
Из диаграммы рис. 29 можно сделать вывод, что от момента Аналогично приведенному выше примеру по данным (9), (10), (11) декодер (рис. 29) принимает решение, что на интервале от момента Главным критерием при выборе сверточного кода является требование, чтобы код не допускал катастрофического распространения ошибок и имел максимальный просвет при данной степени кодирования и длине кодового ограничения. Список наиболее известных кодов со степенью кодирования Таблица3. 12 |


 и будем применять следующее правило:
и будем применять следующее правило:
 и
и  . Узлы также называют состояниями кодера. Ребра - это горизонтальные отрезки, над которыми стоят обозначения 00,01,10 или 11.
. Узлы также называют состояниями кодера. Ребра - это горизонтальные отрезки, над которыми стоят обозначения 00,01,10 или 11. под состоянием кодера будем понимать содержание последних
под состоянием кодера будем понимать содержание последних  ячеек регистра сдвига после подачи информационного символа.
ячеек регистра сдвига после подачи информационного символа.

 , а число ребер как
, а число ребер как 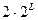 ,где
,где  - номер уровня на диаграмме (рис. 8), т.е. чрезвычайно быстро, что является существенным недостатком древовидных диаграмм. Заметим, что величина
- номер уровня на диаграмме (рис. 8), т.е. чрезвычайно быстро, что является существенным недостатком древовидных диаграмм. Заметим, что величина  связана с номе-
связана с номе-
 информационного символа, подаваемого на вход кодера, простым соотношением
информационного символа, подаваемого на вход кодера, простым соотношением 
 ), полностью тождественны. Это является причиной того, что, начиная с уровня 3, верхнее и нижнее поддеревья также одинаковы, поэтому их можно отождествить. В результате вместо древовидной диаграммы Д.Форни получил решетчатую диаграмму, изображенную на рис. 9, в которой отмеченный выше недостаток древовидной диаграммы отсутствует. Решетчатая диаграмма также состоит из ребер и узлов.
), полностью тождественны. Это является причиной того, что, начиная с уровня 3, верхнее и нижнее поддеревья также одинаковы, поэтому их можно отождествить. В результате вместо древовидной диаграммы Д.Форни получил решетчатую диаграмму, изображенную на рис. 9, в которой отмеченный выше недостаток древовидной диаграммы отсутствует. Решетчатая диаграмма также состоит из ребер и узлов.
 Узлы, расположенные вдоль второй горизонтали, также имеют одно состояние
Узлы, расположенные вдоль второй горизонтали, также имеют одно состояние  Вдоль третьей горизонтали узлы имеют состояние
Вдоль третьей горизонтали узлы имеют состояние 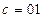 и вдоль четвертой горизонтали состояние
и вдоль четвертой горизонтали состояние 
 , из которых выходят 4-е ребра. Из узла
, из которых выходят 4-е ребра. Из узла  ) число вершин в решетчатой диаграмме не растет, а остается равным
) число вершин в решетчатой диаграмме не растет, а остается равным  (где
(где  длина кодового ограничения). В рассматриваемом примере кодера
длина кодового ограничения). В рассматриваемом примере кодера 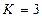 , поэтому получаем
, поэтому получаем  На древовидной диаграмме, как уже отмечалось, при увеличении номеров уровней происходит катастрофический рост числа узлов и соответственно ребер, что делает древовидные диаграммы менее привлекательными для практического использования, особенно при декодировании.
На древовидной диаграмме, как уже отмечалось, при увеличении номеров уровней происходит катастрофический рост числа узлов и соответственно ребер, что делает древовидные диаграммы менее привлекательными для практического использования, особенно при декодировании. , которое меньше, чем
, которое меньше, чем  где
где  символов или более, то при свёрточном декодировании каждая из этих ошибок исправляется независимо от другой ошибки, т.е. как одиночная ошибка;
символов или более, то при свёрточном декодировании каждая из этих ошибок исправляется независимо от другой ошибки, т.е. как одиночная ошибка; символов, то независимое исправление в общем случае уже невозможно, так как процесс исправления первой ошибки еще может не закончиться, а декодер приступит к исправлению второй ошибки, и на каком-то временном интервале одновременно исправляются обе ошибки (или большее число ошибок).
символов, то независимое исправление в общем случае уже невозможно, так как процесс исправления первой ошибки еще может не закончиться, а декодер приступит к исправлению второй ошибки, и на каком-то временном интервале одновременно исправляются обе ошибки (или большее число ошибок).
 . Исследования сверточных кодов показали, что и для них количество исправляемых ошибок
. Исследования сверточных кодов показали, что и для них количество исправляемых ошибок  (8).
(8). , то при сверточном декодировании можно исправить две ошибки, т.е.
, то при сверточном декодировании можно исправить две ошибки, т.е.  , так как
, так как 
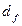 , который называется минимальным просветом или просто просветом. Более подробно об этом параметре будет изложено в дальнейшем.
, который называется минимальным просветом или просто просветом. Более подробно об этом параметре будет изложено в дальнейшем. - последовательность информационных символов, поступивших на вход кодера;
- последовательность информационных символов, поступивших на вход кодера; - последовательность кодовых символов с выхода кодера, которая передавалась по каналу;
- последовательность кодовых символов с выхода кодера, которая передавалась по каналу; - принятая последовательность, полученная с выхода демодулятора и поступившая на вход декодера.
- принятая последовательность, полученная с выхода демодулятора и поступившая на вход декодера.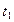 (рис. 10). В результате очистки кодера между сообщениями будем считать, что декодер находится в начальном состоянии
(рис. 10). В результате очистки кодера между сообщениями будем считать, что декодер находится в начальном состоянии  00 00 00 00 00 00 (10),
00 00 00 00 00 00 (10), , то эти две ошибки должны быть исправлены при использовании алгоритма свёрточного декодирования Витерби.
, то эти две ошибки должны быть исправлены при использовании алгоритма свёрточного декодирования Витерби.
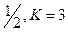 ).
). , для дальнейшего удобства обозначим буквами узлы на этой диаграмме.
, для дальнейшего удобства обозначим буквами узлы на этой диаграмме.
 и приходящих в узлы
и приходящих в узлы  . Видим, что в узел
. Видим, что в узел  приходят два пути:
приходят два пути:  и
и  . Определим по диаграмме метрику этих путей:
. Определим по диаграмме метрику этих путей:
 также приходят два пути:
также приходят два пути:  и
и  ; их метрики равны:
; их метрики равны: .
. также приходят два пути:
также приходят два пути:  и
и  ; их метрики равны:
; их метрики равны: .
. также приходят два пути;
также приходят два пути;  и
и  ; их метрики равны:
; их метрики равны: .
.
 (из каждого узла
(из каждого узла 
 приходят два пути:
приходят два пути:  и
и  ; метрика этих путей равна:
; метрика этих путей равна: .
. также приходят два пути:
также приходят два пути:  и
и 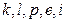 ; находим
; находим .
. и
и  .
. .
. также приходят пути:
также приходят пути:  и.
и.  .
. .
.

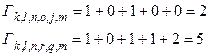



 строим на диаграмме эти пути (рис. 15).
строим на диаграмме эти пути (рис. 15).
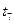 .
. .
.


 ;
; 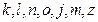 ;
;  ;
;  .
.
 .
.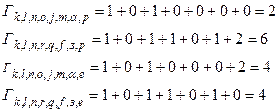

 .
.
 ;
;  ;
;  ;
;  ;
;
 выжил только один путь
выжил только один путь 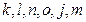 . Теперь перенесем этот один выживший путь
. Теперь перенесем этот один выживший путь 
 и
и  , то определяются расстояния Хемминга между этой парой символов и парами символов, которыми отмечены ребра решетчатой диаграммы кодера между теми же моментами времени
, то определяются расстояния Хемминга между этой парой символов и парами символов, которыми отмечены ребра решетчатой диаграммы кодера между теми же моментами времени  ) и заканчиваются в узлах решетки декодера для момента
) и заканчиваются в узлах решетки декодера для момента 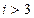 ) имеем четыре узла и в каждый узел приходят два пути (все они начинаются в одной той же точке
) имеем четыре узла и в каждый узел приходят два пути (все они начинаются в одной той же точке  .
. =00 00 00 00 00 00 (12)
=00 00 00 00 00 00 (12) также нулевая, т.е.
также нулевая, т.е.
 . Эти пути обозначим:
. Эти пути обозначим:  .
.

 ) величина просвета
) величина просвета  . Эта величина
. Эта величина  . Следовательно, величину просвета
. Следовательно, величину просвета  символов.
символов. = 00 00 00 00 00 00 00 (14),
= 00 00 00 00 00 00 00 (14), = 01 10 00 00 00 00 00 (15).
= 01 10 00 00 00 00 00 (15).


 ;
;  .
. рис. 29 отмечены знаком
рис. 29 отмечены знаком  .
.


 , достроенные до момента
, достроенные до момента 
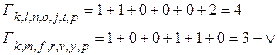








 .
.




 .
.

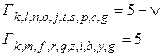


 . Перенесем этот выживший путь с диаграммы декодера на диаграмму кодера (рис. 9).
. Перенесем этот выживший путь с диаграммы декодера на диаграмму кодера (рис. 9). :00 00 00 00 00 00 00 (14) от момента
:00 00 00 00 00 00 00 (14) от момента 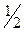 , если
, если  , если
, если