| ПОЗНАВАТЕЛЬНОЕ Сила воли ведет к действию, а позитивные действия формируют позитивное отношение Как определить диапазон голоса - ваш вокал Игровые автоматы с быстрым выводом Как самому избавиться от обидчивости Противоречивые взгляды на качества, присущие мужчинам Вкуснейший "Салат из свеклы с чесноком" Натюрморт и его изобразительные возможности Применение, как принимать мумие? Мумие для волос, лица, при переломах, при кровотечении и т.д. Как научиться брать на себя ответственность Зачем нужны границы в отношениях с детьми? Световозвращающие элементы на детской одежде Как победить свой возраст? Восемь уникальных способов, которые помогут достичь долголетия Классификация ожирения по ИМТ (ВОЗ) Глава 3. Завет мужчины с женщиной
Оси и плоскости тела человека - Тело человека состоит из определенных топографических частей и участков, в которых расположены органы, мышцы, сосуды, нервы и т.д.
| Методы предварительной обработки текста
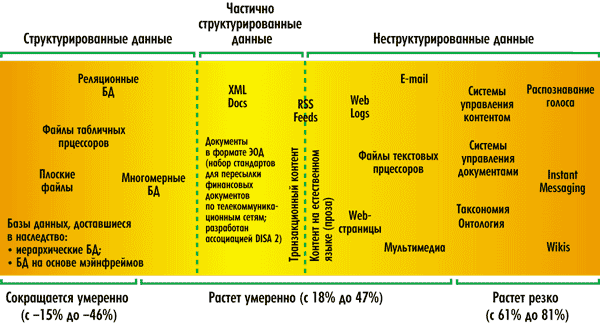
Задача анализа текстов Впервые «ручные» техники Text Mining появились в середине 1980-х, а в следующее десятилетие развитие технологий позволило значительно их усовершенствовать. В междисциплинарном смысле Text Mining лежит на стыке поиска информации, Data Mining, машинного самообучения, статистики и компьютерной лингвистики. Например, текстовые документы практически невозможно преобразовать в табличное представление без потери семантики текста и отношений между сущностями. По этой причине такие документы хранятся в БД без преобразований, как текстовые поля (BLOB-поля). В то же время в тексте скрыто огромное количество информации, но ее неструктурированность не позволяет использовать алгоритмы Data Mining. Решением этой проблемы занимаются методы анализа неструктурированного текста. В западной литературе такой анализ называют Text Mining. Text Mining часто называют также текстовым дейтамайнингом (text data mining), что отчасти раскрывает взаимосвязь двух этих технологий. Если дейтамайнинг позволяет извлекать новые знания (скрытые закономерности, факты, неизвестные взаимосвязи и т.п.) из больших объемов структурированной информации (хранимой в базах данных), то текстомайнинг — находить новые знания в неструктурированных текстовых массивах. В этом смысле Text Mining добавляет к технологии data mining дополнительный этап — перевод неструктурированных текстовых массивов в структурированные. После чего данные могут обрабатываться с помощью стандартных методов data mining. Методы анализа в неструктурированных текстах лежат на стыке нескольких областей: Data Mining, обработка естественных языков, поиск информации, извлечение информации и управление знаниями. Типичные задачи Text Mining включают категоризацию, кластеризацию текстов, извлечение концептов и объектов, создание таксономий, смысловой анализ, обобщение документации и моделирование объектов, то есть установление связей между различными известными объектами. Анализ текстов включает себя извлечение информации и лингвистический анализ для выявления частоты вхождений различных слов, выявление шаблонов, расставление тэгов и аннотирование, техники Data Mining, включая анализ связей и ассоциаций, визуализацию и прогностический анализ. В конечном счете, общая цель всего этого состоит в том, чтобы превратить текст в данные, доступные для анализа. Наиболее простой задачей является Text Mining слабоструктурированных узкоспециализированных текстовых массивов (различные отчеты о поломках, результаты опросов и т.п.). В текстовых массивах, где форма документа и набор лексики ограничены, новую информацию можно извлекать, анализируя статистику на уровне отдельных ключевых слов (терминов). Когда мы говорим о неструктурированных текстах, то в общем виде задача сводится к «пониманию» произвольных текстов на естественном языке — это одна из старейших задач искусственного интеллекта (ИИ), которая может решаться с использованием различных технологий, в первую очередь на базе методов обработки данных на естественном языке — NLP (Natural Language Processing), на основе нейросетевых подходов, а также других методов и их комбинаций. Огромное количество информации скапливается в многочисленных текстовых базах, хранящихся в личных ПК, локальных и глобальных сетях. И объем этой информации стремительно увеличивается. Чтение объемных текстов и поиск в гигантских массивах текстовых данных малоэффективны, поэтому становятся все более востребованными решения Text Mining. Актуальность Text Mining растет по мере того, как людям самых разных профессий приходится принимать решения на базе анализа большого объема неструктурированных и слабоструктурированных текстов (рис. 1).
Рис. 1. (источник: Businessobjects)
Все более интересным становится анализ общественного мнения, выраженного в Web, в том числе блогосфера. Одним из новых направлений текстомайнинга является Opinion Mining (OM) (буквально — раскопка мнений) — технология, которая концентрируется не столько на содержании документа, сколько на мнении, которое он выражает. Оценить успешность проведенной рекламной кампании, узнать, как к фирме относятся в прессе, — на эти и другие вопросы можно получить ответ с помощью технологии Opinion Mining.
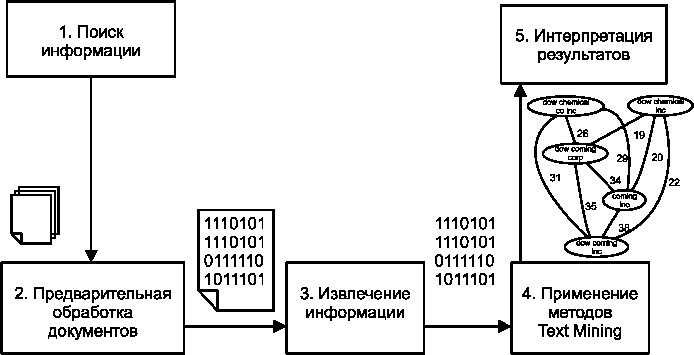
Процесс анализа текстовых документов можно представить как последовательность нескольких шагов (рис. 2).
Рис. 2. Этапы Text Mining
Поиск информации. На первом шаге необходимо идентифицировать, какие документы должны быть подвергнуты анализу, и обеспечить их доступность. Предварительная обработка документов. На этом шаге выполняются простейшие, но необходимые преобразования с документами для представления их в виде, с которым работают методы Text Mining. Целью таких преобразований является удаление лишних слов и придание тексту более строгой формы. Извлечение информации. Извлечение информации из выбранных документов предполагает выделение в них ключевых понятий, над которыми в дальнейшем будет выполняться анализ. Применение методов Text Mining. На данном шаге извлекаются шаблоны и отношения, имеющиеся в текстах. Данный шаг является основным в процессе анализа текстов. Интерпретация результатов. Последний шаг в процессе обнаружения знаний предполагает интерпретацию полученных результатов. Как правило, интерпретация заключается или в представлении результатов на естественном языке, или в их визуализации в графическом виде. Визуализация также может быть использована как средство анализа текста. Для этого извлекаются ключевые понятия, которые и представляются в графическом виде. Такой подход помогает пользователю быстро идентифицировать главные темы и понятия, а также определить их важность. Важная задача технологии Text Mining связана с извлечением из текста его характерных элементов или свойств, которые могут использоваться как метаданные документа, ключевых слов, аннотаций. Другая важная задача состоит в отнесении документа к некоторым категориям из заданной схемы их систематизации. Text Mining также обеспечивает новый уровень семантического поиска документов. Возможности современных систем Text Mining могут применяться при управлении знаниями для выявления шаблонов в тексте, для автоматического «выталкивания» или размещения информации по интересующим пользователей профилям, создавать обзоры документов
Методы предварительной обработки текста Одной из главных проблем анализа текстов является большое количество слов в документе. Если каждое из этих слов подвергать анализу, то время поиска новых знаний резко возрастет и вряд ли будет удовлетворять требованиям пользователей. В то же время очевидно, что не все слова в тексте несут полезную информацию. Кроме того, в силу гибкости естественных языков формально различные слова (синонимы и т.п.) на самом деле означают одинаковые понятия. Таким образом, удаление неинформативных слов, а также приведение близких по смыслу слов к единой форме значительно сокращают время анализа текстов. Устранение описанных проблем выполняется на этапе предварительной обработки текста. Обычно используют следующие приемы удаления неинформативных слов и повышения строгости текстов: · удаление стоп-слов. Стоп-словами называются слова, которые являются вспомогательными и несут мало информации о содержании документа. Обычно заранее составляются списки таких слов, и в процессе предварительной обработки они удаляются из текста. Типичным примером таких слов являются вспомогательные слова и артикли, например: "так как", "кроме того" и т. п.; · стемминг — морфологический поиск. Он заключается в преобразовании каждого слова к его нормальной форме. Нормальная форма исключает склонение слова, множественную форму, особенности устной речи и т. п. Например, слова "сжатие" и "сжатый" должны быть преобразованы в нормальную форму слова "сжимать". Алгоритмы морфологического разбора учитывают языковые особенности и вследствие этого являются языковозависимыми алгоритмами; · N-граммы — это альтернатива морфологическому разбору и удалению стоп-слов. N-грамма — это часть строки, состоящая из N символов. Например, слово "дата" может быть представлено 3-граммой "_да", "дат", "ата", "та_" или 4-граммой "_дат", "дата", "ата_", где символ подчеркивания заменяет предшествующий или замыкающий слово пробел. По сравнению со стеммингом или удалением стоп-слов, N-граммы менее чувствительны к грамматическим и типографическим ошибкам. Кроме того, N-граммы не требуют лингвистического представления слов, что делает данный прием более независимым от языка. Однако N-граммы, позволяя сделать текст более строгим, не решают проблему уменьшения количества неинформативных слов; · приведение регистра. Этот прием заключается в преобразовании всех символов к верхнему или нижнему регистру. Например, все слова "текст", "Текст", "ТЕКСТ" приводятся к нижнему регистру "текст". Наиболее эффективно совместное применение перечисленных методов.
Задачи Text Mining Задачи Text Mining: классификация, кластеризация, и характерные только для текстовых документов задачи: автоматическое аннотирование, извлечение ключевых понятий и др. Классификация (classification) — стандартная задача из области Data Mining. Ее целью является определение для каждого документа одной или нескольких заранее заданных категорий, к которым этот документ относится. Особенностью задачи классификации является предположение, что множество классифицируемых документов не содержит "мусора", т. е. каждый из документов соответствует какой-нибудь заданной категории. Частным случаем задачи классификации является задача определения тематики документа. В существующих сегодня системах классификация применяется, например, в таких задачах: группировка документов в intranet- сетях и на Web-сайтах, размещение документов в определенные папки, сортировка сообщений электронной почты, избирательное распространение новостей подписчикам. М Целью кластеризации (clustering) документов является автоматическое выявление групп семантически похожих документов среди заданного фиксированного множества. Отметим, что группы формируются только на основе попарной схожести описаний документов, и никакие характеристики этих групп не задаются заранее. Автоматическое аннотирование (summarization) позволяет сократить текст, сохраняя его смысл. Решение этой задачи обычно регулируется пользователем при помощи определения количества извлекаемых предложений или процентом извлекаемого текста по отношению ко всему тексту. Результат включает в себя наиболее значимые предложения в тексте. Первичной целью извлечения ключевых понятий (feature extraction) является идентификация фактов и отношений в тексте. В большинстве случаев такими понятиями являются имена существительные и нарицательные: имена и фамилии людей, названия организаций и др. Алгоритмы извлечения понятий могут использовать словари, чтобы идентифицировать некоторые термины и лингвистические шаблоны для определения других. Навигация по тексту (text-base navigation) позволяет пользователям перемещаться по документам относительно тем и значимых терминов. Это выполняется за счет идентификации ключевых понятий и некоторых отношений между ними.
|