| ПОЗНАВАТЕЛЬНОЕ Сила воли ведет к действию, а позитивные действия формируют позитивное отношение Как определить диапазон голоса - ваш вокал Игровые автоматы с быстрым выводом Как самому избавиться от обидчивости Противоречивые взгляды на качества, присущие мужчинам Вкуснейший "Салат из свеклы с чесноком" Натюрморт и его изобразительные возможности Применение, как принимать мумие? Мумие для волос, лица, при переломах, при кровотечении и т.д. Как научиться брать на себя ответственность Зачем нужны границы в отношениях с детьми? Световозвращающие элементы на детской одежде Как победить свой возраст? Восемь уникальных способов, которые помогут достичь долголетия Классификация ожирения по ИМТ (ВОЗ) Глава 3. Завет мужчины с женщиной
Оси и плоскости тела человека - Тело человека состоит из определенных топографических частей и участков, в которых расположены органы, мышцы, сосуды, нервы и т.д.
| Извлечение ключевых понятий из текста
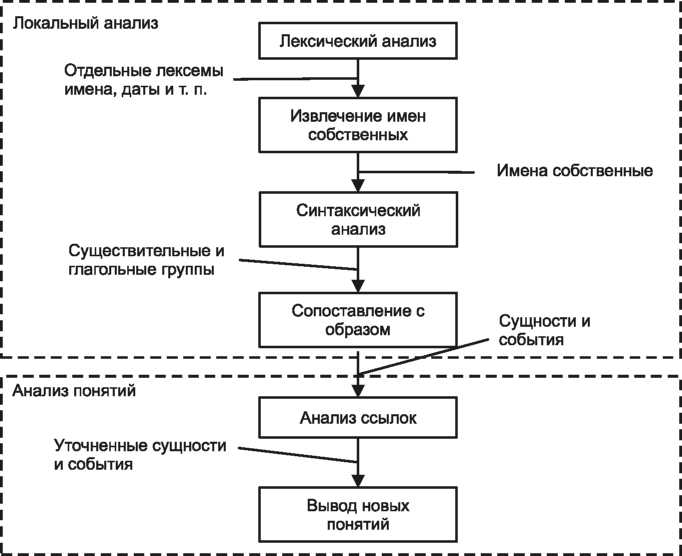
Извлечение ключевых понятий из текста может рассматриваться и как отдельный этап анализа текста, и как определенная прикладная задача. В первом случае извлеченные из текста факты используются для решения различных задач анализа: классификации, кластеризации и др. Большинство методов Data Mining, адаптированные для анализа текстов, работают именно с такими отдельными понятиями, рассматривая их в качестве атрибутов данных. В задаче извлечения ключевых понятий из текста интерес представляют некоторые сущности, события и отношения. При этом извлеченные понятия анализируются и используются для вывода новых. Извлечение ключевых понятий из текстовых документов можно рассматривать как фильтрацию больших объемов текста. Этот процесс включает в себя отбор документов из коллекции и пометку определенных термов в тексте. Существуют различные подходы к извлечению информации из текста. Примером может служить определение частых наборов слов и объединение их в ключевые понятия. Другим подходом является идентификация фактов в текстах и извлечение их характеристик. Фактами являются некоторые события или отношения. Идентификация производится с помощью наборов образцов. Образцы представляют собой возможные лингвистические варианты фактов. Такой подход позволяет представить найденные ключевые понятия, представленные событиями и отношениями, в виде структур, которые в том числе можно хранить в базах данных. Процесс извлечения ключевых понятий с помощью шаблонов разбивается на две стадии: локальный анализ и анализ понятий (рис. 3). На первой стадии из текстовых документов извлекаются отдельные факты с помощью лексического анализа. Вторая стадия заключается в интеграции извлеченных фактов и/или в выводе новых фактов. В конце наиболее характерные факты преобразовываются в нужную выходную форму.
Рис. 3. Процесс извлечения ключевых понятий
На стадии интеграции найденные в документах факты исследуются и комбинируются. Это выполняется с учетом отношений, которые определяются местоимениями или описанием одинаковых событий. Также на этой стадии делаются выводы из ранее установленных фактов. Извлечение фактов выполняется при помощи сопоставления текста с набором регулярных выражений (образцов). Если выражение сопоставляется с текстовыми сегментами, то такие сегменты помечаются метками. При необходимости этим сегментам приписываются дополнительные свойства. Образцы организуются в наборы. Метки, ассоциированные с одним набором, могут ссылаться на другие наборы. Каждый образец имеет связанный с ним набор действий. Как правило, главное действие — это пометить текстовый сегмент новой меткой, но могут быть и другие действия. В каждый момент времени текстовому сегменту сопоставляется только один набор образцов. Каждый образец в наборе начинает сопоставляться с первого слова предложения. Если образец может быть сопоставлен более чем одному сегменту, то выбирается наиболее длинный сопоставленный сегмент. Если таких сегментов несколько, то выбирается первый. При сопоставлении выполняются действия, ассоциированные с этим образцом. Если не удалось сопоставить ни один образец, то сопоставление повторяется, начиная со следующего слова в предложении. Если сегмент сопоставлен с образцом, то сопоставление повторяется, начиная со следующего слова после сегмента. Процесс продолжается до конца предложения. Основной целью сопоставления с образцами является выделение в тексте сущностей, связей и событий. Все они могут быть преобразованы в некоторые структуры, которые могут анализироваться стандартными методами Data Mining.
|