| ПОЗНАВАТЕЛЬНОЕ Сила воли ведет к действию, а позитивные действия формируют позитивное отношение Как определить диапазон голоса - ваш вокал Игровые автоматы с быстрым выводом Как самому избавиться от обидчивости Противоречивые взгляды на качества, присущие мужчинам Вкуснейший "Салат из свеклы с чесноком" Натюрморт и его изобразительные возможности Применение, как принимать мумие? Мумие для волос, лица, при переломах, при кровотечении и т.д. Как научиться брать на себя ответственность Зачем нужны границы в отношениях с детьми? Световозвращающие элементы на детской одежде Как победить свой возраст? Восемь уникальных способов, которые помогут достичь долголетия Классификация ожирения по ИМТ (ВОЗ) Глава 3. Завет мужчины с женщиной
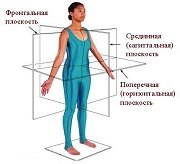
Оси и плоскости тела человека - Тело человека состоит из определенных топографических частей и участков, в которых расположены органы, мышцы, сосуды, нервы и т.д.
| Классификация по способу обработки данных и типу операндов
Эта классификация, на наш взгляд, более удобна с точки зрения практики обучения. Особенно это проявляется при изучении языка ассемблера. Независимо от архитектуры ЭВМ все команды ЦП можно разделить на две большие группы: 1. Команды привилегированные. 2. Команды непривилегированные. Первая группа, иногда называемая командами, выполняющимися в режиме «супервизор/система», предоставляет пользователю возможность использовать все ресурсы ЭВМ. Вторая группа, называемая командами, выполняющимися в режиме «задача/пользователь», ограничивает использование некоторых возможностей ЭВМ. Внутри каждой из этих групп можно выделить подгруппы, характеризующие характер действий, вид обрабатываемой информации, выполняемые действия. Напомним, что в классической ЭВМ команды программы выполняются в порядке их расположения в памяти, то для получения адреса очередной команды достаточно увеличить содержимое программного счетчика на длину текущей команды. Для изменения такого порядка исполнения команд в ЭВМ включаются команды, позволяющие передать управление в другую точку программы. В адресной части таких команд содержится адрес точки перехода. В современных ЭВМ можно выделить три типа команд, способных изменить последовательность вычислений: · безусловные переходы; · условные переходы (ветвления); · вызовы подпрограмм (процедур) и возвраты из них. В английском языке для указания команд безусловного перехода, как правило, используется термин jump (скачок), а для команд условного перехода – терминbranch (переход), хотя разные фирмы необязательно придерживаются этой терминологии. Например, компания Intel использует термин jump и для условных, и для безусловных переходов. Частота использования этих команд по статистике примерно следующая. В программах доминируют команды условного перехода. Среди указанных команд управления на разных программах частота их использования колеблется от 66 до 78%. Следующие по частоте использования - команды безусловного перехода (от 12 до 18%). Частота переходов на выполнение процедур и возврата из них составляет от 10 до 16%. При этом примерно 90% команд безусловного перехода выполняются относительно программного счетчика. Для команд перехода адрес перехода должен быть всегда заранее известным. Это не относится к адресам возврата, которые не известны во время компиляции программы и должны определяться во время ее работы. Переход можно организовать следующими способами: 1. Переход относительно текущего значения программного счетчика. 2. Переход и возврат по косвенному адресу. Наиболее простой способ определения адреса перехода заключается в указании его положения относительно текущего значения программного счетчика (с помощью смещения в команде), и такие переходы называются переходами относительно программного счетчика. Преимуществом такого метода адресации является то, что адреса переходов, как правило, расположены недалеко от текущего адреса выполняемой команды и указание относительно текущего значения программного счетчика требует небольшого количества бит в смещении. Кроме того, использование адресации относительно программного счетчика позволяет программе выполняться в любом месте памяти, независимо от того, куда она была загружена. То есть, этот метод адресации позволяет автоматически создавать перемещаемые программы. Реализация возвратов и переходов по косвенному адресу, в которых адрес не известен во время компиляции программы, требует методов адресации, отличных от адресации относительно программного счетчика. В этом случае адрес перехода должен определяться динамически во время работы программы. Наиболее простой способ заключается в указании регистра для хранения адреса возврата. Один из ключевых вопросов реализации команд перехода состоит в том, насколько далеко целевой адрес перехода находится от самой команды перехода (глубина перехода)? И на этот вопрос статистика использования команд дает ответ: в подавляющем большинстве случаев переход идет в пределах (3-7) команд относительно команды перехода, причем в 75% случаев выполняются переходы в направлении увеличения адреса, т.е. вперед по программе. Поскольку большинство команд управления составляют команды условного перехода, важным вопросом реализации архитектуры является определение условий перехода. Для этого используются три различных подхода. При первом из них в архитектуре процессора предусматривается специальный регистр, разряды которого соответствуют определенным кодам условий. Команды условного перехода проверяют эти условия в процессе своего выполнения. Преимуществом такого подхода является то, что иногда установка кода условия и переход по нему могут быть выполнены без дополнительных потерь времени, что, впрочем, бывает достаточно редко. А недостатками такого подхода является то, что, во-первых, появляются новые состояния машины, за которыми необходимо следить (скрывать при прерывании и восстанавливать при возврате из него). Кроме того, и что очень важно для современных высокоскоростных конвейерных архитектур, коды условий ограничивают порядок выполнения команд в потоке, поскольку их основное назначение заключается в передаче кода условия команде условного перехода. Второй метод заключается в простом использовании произвольного регистра (возможно одного выделенного) общего назначения. В этом случае выполняется проверка состояния этого регистра, в который предварительно помещается результат операции сравнения. Недостатком этого подхода является необходимость выделения в программе для анализа кодов условий специального регистра. Третий метод предполагает объединение оператора сравнения и перехода в одной команде. Недостатком такого подхода является то, что эта объединенная команда довольно сложна для реализации (в одной команде надо указать и тип условия, и константу для сравнения, и адрес перехода). Поэтому в таких машинах часто используется компромиссный вариант, когда для некоторых кодов условий используются такие команды, например, для сравнения с нулем, а для более сложных условий используется регистр условий. Часто для анализа результатов команд сравнения для целочисленных операций и для операций с плавающей точкой используется разная техника, хотя это можно объяснить и тем, что в программах количество переходов по условиям выполнения операций с плавающей точкой значительно меньше общего количества переходов, определяемых результатами работы целочисленной арифметики. Одним из наиболее заметных свойств большинства программ является преобладание в них сравнений на условие «равно/неравно» и сравнений с нулем. Поэтому в ряде архитектур такие команды выделяются в отдельный поднабор, особенно при использовании команд типа «сравнить и перейти». Переход выполняется, если истинным является условие, которое проверяет команда условного перехода. В этом случае выполняется переход на адрес, заданный командой перехода. Поэтому все команды безусловного перехода всегда выполняемые. По статистике оказывается, что переходы назад по программе в большинстве случаев используются для организации циклов, причем примерно 60% из них составляют выполняемые переходы. В общем случае поведение команд условного перехода зависит от конкретной прикладной программы, однако иногда сказывается и зависимость от компилятора. Такие зависимости от компилятора возникают вследствие изменений потока управления, выполняемого оптимизирующими компиляторами для ускорения выполнения циклов. Вызовы процедур и возвраты предполагают передачу управления и возможно сохранение некоторого состояния. Как минимум, необходимо уметь где-то сохранять адрес возврата. Некоторые архитектуры предлагают аппаратные механизмы для сохранения состояния регистров, в других случаях предполагается вставка в программу команд самим компилятором. Имеются два основных вида соглашений относительно сохранения состояния регистров. Сохранение вызывающей (caller saving) программойозначает, что вызывающая процедура должна сохранять свои регистры, которые она хочет использовать после возврата в нее. Сохранение вызванной процедурой предполагает, что вызванная процедура должна сохранить регистры, которые она собирается использовать. Имеются случаи, когда должно использоваться сохранение вызывающей процедурой для обеспечения доступа к глобальным переменным, которые должны быть доступны для обеих процедур. Форматы команд Уже отмечалось (см. рис. 2.2), что формат команд определяет ее структуру, т.е. количество двоичных разрядов, отводимых под команду, а также количество и расположение отдельных полей команды. При разработке системы команд обычно учитывают следующие факторы: 1. общее число команд, входящих в систему; 2. общую длину команды; 3. тип полей команды и их длину; 4. простоту декодирования; 5. адресуемость и способы адресации; 6. стоимость оборудования для декодирования и исполнения команд. Следует отметить, что длина команды существенно влияет на организацию и емкость ОП, структуру шин, сложность и быстродействие ЦП. Чем больше команд входит в систему команд и чем они длиннее, тем можно больше использовать способов адресации, большее число кодов операций, можно обращаться к большему объему ОП. Однако такой подход требует выделения большего количества разрядов под каждое поле команды, что в свою очередь приводит к увеличению времени выборки команды, расширению шины и, как результат, – усложнению аппаратуры. На практике длину команды выбирают кратной байту, т.к. в большинстве современных ЭВМ ОП построена по байтному принципу. В связи с использованием различных способов адресации в систему команд включают команды различной длины. Общая длина команды Lk может быть описана следующим соотношением:
где n – количество адресов в команде; Ri – количество разрядов для записей i-го операнда; RКОП – разрядность поля для кода операции (КОП); RСА – разрядность поля способа адресации (СА). Количество разрядов под поле для КОП выбирают так, чтобы можно было представить любую из операций. Если система команд включает NКОП различных операций, то минимальная разрядность поля под КОП RКОП определяется выражением:
где int – округление в большую сторону до целого числа. С целью нахождения оптимального соотношения между полями под КОП и адресной частью, иногда поле КОП делают переменным. Изначально под поле КОП выделяют фиксированное число разрядов, но для отдельных команд длина поля может увеличиваться за счет добавления определенного числа разрядов из адресного поля. Адресная часть команды содержит информацию о местонахождении данных и месте хранения результата операции. Адреса операндов и результата задаются указанием либо номеров регистров, либо соответствующими именами, обозначающими номера ячеек ОП. Разрядность полей Ri и RСА можно рассчитать по нижеследующим формулам:
где Ni –количество ячеек ОП, к которому можно обратиться с помощью i‑го адреса; NСА – количество способов адресации. Таким образом,
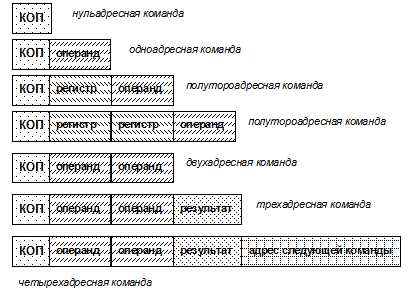
Рис. 2.4. Форматы команд мейнфреймов фирмы IBM Количество адресов в команде в различных ЭВМ различно. В общем случае можно использовать следующие форматы команд: · нульадресный; · одноадресный; · полуторадресный; · двухадресный; · трехадресный; · четырехадресный. На рис. 2.4 представлены все перечисленные выше форматы команд для ЭВМ фирмы IBM. Команда «КОП/регистр/регистр/операнд» может быть одноадресной или полутороадресной в зависимости от длины поля, отводимого для размещения номера регистра. Четырехадресные форматы команд применялись в первые годы создания ЭВМ. Одной из таких ЭВМ была EDVAC. Трехадресные форматы часто использовались в ЭВМ 60-х годов. В настоящее время используются наиболее часто двухадресные команды, хотя в системе команд ЭВМ могут быть и другие форматы, кроме четырехадресных. При выборе того или иного формата команд учитывают такие факторы как: · емкость ОП, требуемой для хранения программы; · время выполнения программы; · эффективность использования ячеек ОП при хранении программы. На рис. 2.5 приведен обобщенный формат команд ЭВМ с МП архитектуры x86 (Intel, AMD).
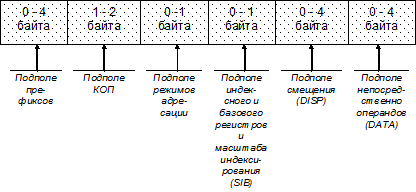
Рис. 2.5. Обобщенный формат команд ЭВМ архитектуры x86 Как следует из рис. 2.5 формат команды является переменным. В младших моделях длина команды составляет от 1 до 6 байтов, в старших длина команды может иметь длину до 11 байтов. Остальные 5 байтов оставлены для будущих расширений. В подполе префиксов размещаются следующая информация: · префикс команды (повторения или блокировки доступа к шине данных); · префикс переопределения сегмента; · префикс переопределения размера операнда (для старших моделей); · префикс переполнения размера адреса (для старших моделей). При выборе того или иного формата команды учитывают время выполнения команды, которое складывается из времени непосредственно выполнения команды и времени обращения к памяти. При использовании одноадресных команд необходимо два обращения к памяти: выборка команды и выборка операнда. При выполнении же 3-х адресной команды таких обращений нужно четыре: выборка команды, выбора 1-го операнда, выборка 2-го операнда, запись в память результата. В общем случае время выполнения программы можно оценить по следующему соотношению:
где N1 – количество арифметических и логических команд в программе; t1A – время выполнения одной арифметической или логической команды; N2 – количество неарифметических команд; t2A – время выполнения одной неарифметической команды. А = {1, 2, 3} – индекс, определяющий количество адресов в команде. В свою очередь N2 можно представить как
где N21 – количество команд передачи управления (их число не зависит от адресности); N22 – количество вспомогательных команд пересылок данных в регистр сумматора и из него. Времена t1A и t2A складываются из времени выборки команды из памяти t0 (время на одно обращение к памяти) и времени считывания/записи данных А∙t0. В случае арифметической команды следует также учитывать время выполнения арифметической операции t1. Таким образом, имеем:
Тогда выражение (2.8) примет вид:
Если подставить в (2.10) значения А=1 для одноадресной и А=3 для трехадресной команды, то можно получить величину DТ - разность времен на реализацию программы с помощью одноадресных и трехадресных команд, принимая во внимание, что для трехадресных команд N22=0. Т1 = N1 ∙(t1 + 2t0) + (N21 + N22)∙2t0 = = N1∙t1 + 2N1∙t0 + 2t0 ∙N21 + 2t0 ∙N22 Т3 = N1 ∙(t1 + 4t0) + (N21 + N22)∙4t0 = = N1∙t1 + 4N1∙t0 + 4t0 ∙N21 DТ = Т1 – Т3 = =N1∙t1 + 2N1∙t0 + 2t0 ∙N21 + 2t0 ∙N22 - N1∙t1 - 4N1∙t0 - 4t0 ∙N21 =
Таким образом,
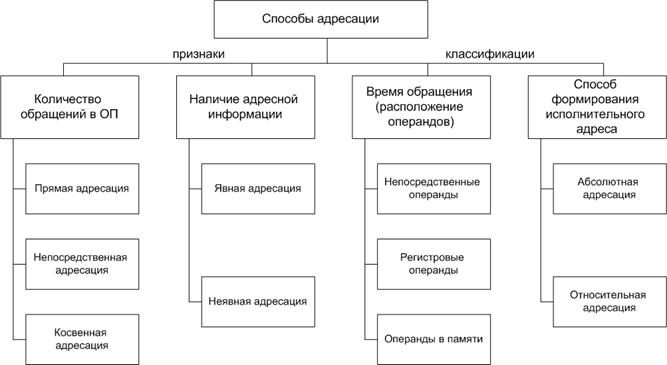
Двухадресные команды в плане времени выполнения программы занимают промежуточное положение между одноадресными и трехадресными. При реализации последовательных алгоритмов одноадресные команды выгодно использовать в тех программах, где больше арифметических и логических команд. При реализации параллельных алгоритмов, если количество параллельных операций больше количества операций передачи управления, выгоднее использовать трехадресные команды. Способы адресации Вопрос о том, каким образом в адресном поле команды может быть указано местоположение операндов, является главным при создании любой ЭВМ. С точки зрения сокращения аппаратных средств очевидно стремление к уменьшению длины адресного поля в команде. Однако, в этом случае программирование на языках низкого уровня весьма отлично от программирования на языках высокого уровня (ЯВУ). С целью сближения конструкций операторов ЯВУ и языков низкого уровня целесообразно иметь большое адресное пространство. Эти противоречия и привели к тому, что в системе команд ЭВМ предусматривается несколько различных способов адресации . В настоящее время существует несколько способов адресации. В основу той или иной классификации положены различные признаки. Основным из них являются: · количество обращений в ОП; · наличие адресной информации; · время обращения (расположение операндов); · способ формирования исполнительного адреса. На нижеследующем рисунке представлен вариант классификации способов адресации по приведенным выше признакам.
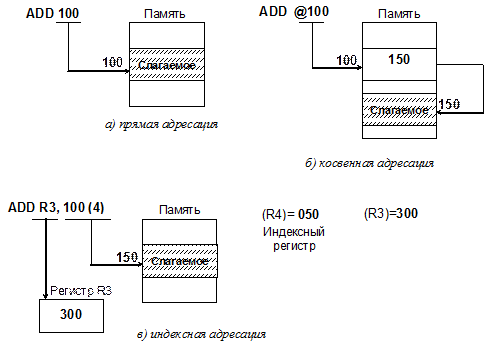
Рис. 2.6. Классификация способов адресации При рассмотрении различных способов адресации будем использовать следующие понятия: 1. Исполнительный адрес операнда(Аисп) – двоичный код номера ячейки памяти, служащей источником или приемником операнда. Этот код подается на адресные входы ОП, и по нему происходит фактическое обращение к указанной ячейке. 2. Адресный код команды (Ак) – двоичный код в адресном поле команды, из которого необходимо сформировать исполнительный адрес операнда. Как правило, Аисп и Ак не совпадают, и для доступа к данным необходимо соответствующее преобразование, которое осуществляется с помощью способа адресации. 3. Способ адресации –это метод формирования исполнительного адреса по адресному коду команды. Различные способы адресации по-разному влияют на процесс обработки информации. Одни способы адресации позволяют увеличить емкость адресуемой памяти без увеличения длины команды, но снижают скорость выполнения команды. Другие способы ускоряют операции над массивами данным, третьи – упрощают работу с подпрограммами и т.п. В современных ЭВМ для выполнения одной и той же операции используют различные способы адресации. Часто различным способам адресации соответствуют различные коды операций. В некоторых случаях в команде может быть несколько таких полей. Возможна ситуация, когда в команде вообще нет адресной информации, так называемая неявная адресация. Рассмотрим наиболее часто используемые способы адресации. Во всех типах современных ЭВМ используется байтовая организация памяти. Байт является минимальной адресуемой частью памяти, состоящей из 8 разрядов (битов). Биты нумеруются справа налево от 0 до 7. Кроме байта используются более крупные единицы измерения памяти: Кбайт (210= 1024 байтов), Мбайт (220 = 1048576 байтов), Гбайт (230=1 073 741 824 байтов), Тбайт (240=1 099 511 627 776 байтов), Пбайт (250), Экобайт (260). Каждый байт памяти имеет свой номер, называемый адресом. Кроме байта, адресовать в памяти можно и более крупные единицы памяти. Рассмотрим эти единицы. Слово - совокупность нескольких смежных байтов, общее число битов в которых равно разрядности ЭВМ. Например, для 32-разрядных машин слово будет составлять 4 байта, для 64-разрядных – 8 байт. Поле- непрерывная по возрастающим значениям адресов последовательность байтов в оперативной памяти. За адрес поля принимается адрес крайнего левого байтаполя. Использование поля той или иной длины определяется типом команды, адресующейся к этому полю. Параграф (только для ЭВМ с архитектурой x86) - совокупность 16 смежных байтов ОП. Адрес параграфа должен быть кратен 16. Страница - некоторая совокупность байтов. Величина ее зависит от класса ЭВМ. Так, для ЭВМ типа РDР-11 размер страницы являлся переменным и колебался от 64 байтов до 8 Кбайт. Применительно к видеопамяти (экран монитора) под страницей понимается содержимое экрана. Сегмент - применительно к ЭВМ с архитектурой x86 - это область ОП, начинающаяся с границы параграфа и имеющая размер до 64Кбайт (216=65536 битов). В старших моделях этих ЭВМ размер сегмента может достигать 4 Гбайт. Для ряда ЭВМ понятие сегмент и страница являются эквивалентными. Наибольшее распространение получили следующие способы адресации: непосредственная, прямая, косвенная и индексная. Схематично три последних способа изображены на рис. 2.7 (а, б, в). Рассмотрим их более подробно.
Рис. 2.7. Способы адресации
При непосредственной адресации сам операнд содержится в адресном поле команды. Этот способ, как правило, используется при выполнении арифметических операций, операций сравнения и для загрузки констант в регистры. Отметим, что при использовании этого способа адресации число обращенийк ОП равно нулю. При прямой адресации в адресном поле команды указывается адрес операнда в памяти (либо номер регистра, содержащего операнд). На рис. 2.7, а) операнд (слагаемое) размещен по адресу 100. Этот адрес и указан в команде сложения ADD 100. При этом способе адресации необходимо однократное обращение к ОП. При косвенной адресации в адресном поле команды указывается адрес ячейки памяти или номер регистра, где содержится адрес операнда. Для выборки операнда необходимо двукратное обращение к памяти – сначала извлекается адрес операнда, а затем – сам операнд. На рис. 2.7, б) адрес операнда (150)расположен по адресу 100, который и указывается в команде ADD @100. Данный вид адресации позволяет реализовать переадресацию данных, т.е. изменять указатель. При индексной адресациик формируемому исполнительному адресу прибавляется значение специального регистра, называемого индексным. На рис. 2.7, в) показан процесс формирования исполнительного адреса при индексной адресации. В качестве индексного регистра используется R4, содержащий число 50. Это число добавляется к адресу 100, указанному в поле команды. По получившемуся исполнительному адресу 150считывается операнд, который складывается с содержимым регистра R3(300). Рассмотрим, как часто используются наиболее распространенные способы адресации. Естественно, что частота использования тех или иных способов адресации существенно зависит от реализованной на ЭВМ системы команд. Так, например, непосредственная адресация предполагает, что если операнд является числом, то оно представляется в дополнительном коде. Если для размещения операнда используется регистр, разрядность которого превышает длину непосредственного операнда, то операнд размещается в младшей части регистра. Существенным недостатком непосредственной адресации является не только то, что в качестве операнда можно использовать только константы, но и то, что размер операнда ограничен длиной адресного поля команды, которое в большинстве случаев меньше длины машинного слова. Проведенные рядом авторов исследования показывают, что в 50-60% команд с непосредственной адресацией длина операнда не превышает 8 бит, а в 75-80% - 16 бит. Средний процент использования непосредственной адресации по всем командам составляет 35% для целочисленных вычислений и 10% - при обработке чисел с ПТ. С точки зрения эффективности непосредственная адресация является «идеальным» способом адресации, с точки зрения стоимости оборудования и временных затрат - не самым лучшим. Прямой способ адресацииимеет существенный недостаток, связанный с ограниченным размером адресного пространства. Кроме того, адрес, указный в команде, не может быть изменен в процессе вычислений, что накладывает ограничение по произвольному размещению программы в памяти. При косвенной адресациисодержимое адресного поля команды остается неизменным, в то время как косвенный адрес в процессе выполнения команды можно изменять. Использование косвенной адресации упрощает обработку массивов, списков и передачу параметров подпрограмм. Недостатком этого способа адресации является необходимость в двукратном обращении к памяти: сначала для извлечения адреса операнда, а затем для обращения к операнду. Кроме того, задействуется лишняя ячейка памяти для хранения исполнительного адреса операнда. Разновидностью прямой и косвенной адресации является регистровая, когда адресное поле команды указывает не на ячейку памяти, а на регистр. При прямой регистровой адресации операнд непосредственно размещается в регистре, при косвенной регистровой – регистр содержит адрес операнда в памяти. Однако широкие возможности по использованию регистрового способа адресации ограничиваются малым числом РОНов в составе процессора. Существует достаточное количество способов адресации с использованием базы и смещения. В этом случае исполнительный адрес формируется путем сложения двух компонент – базового адреса и смещения. Как правило, базовый адрес загружается в специальный регистр базы. Для определения смещения используются уже перечисленные способы адресации – непосредственная, прямая и косвенная, очень часто в сочетании с индексным способом. Главное достоинство адресации с базой и смещением заключается в том, что программа становится легко перемещаемой и может быть загружена практически в любую область памяти. Для перемещения программы из одной области памяти в другую достаточно изменить значение базового адреса. Следует заметить, что для ЭВМ с использованием РОНов затруднительно сделать однозначный вывод о предпочтительности того или иного способа адресации. Можно отметить только тот факт, что интенсивность использования того или иного способа адресации напрямую зависит от характера решаемой задачи. Рассмотрим в качестве примера, способы адресации, используемые в ЭВМ фирмы IBM. В мэйнфреймахсерии IBM– S/360/370/390 и др. имеется как минимум 16 регистров общего назначения (РОН) длиной в 4 байта (слово) каждый и 4 регистра для обработки данных с плавающей точкой (ПТ) длиной в 8 байтов (двойное слово), которые называют регистры с плавающей точкой (запятой) РПТ (РПЗ). При обращении к регистрам используют их номера 0, 1, 2, … , N. В современных мэйнфреймах используется 64-разрядный адрес, хотя ранее выпускались ЭВМ с 24- и 32-разрадной адресацией. Значение, которое можно разместить в отведенное адресное пространство, определяет абсолютныйили исполнительный адрес. Для машин серии IBM S/360/370 величина такого адреса равнялась 224-1 = 16777215 = 16 Мб. Для последующих моделей это значение равнялось (232-1) 4 Гб и (263-1) байт. Следует заметить, что абсолютный адрес программистом не используется, а вычисляется операционной системой (ОС). Пользователь в своей программе использует относительные адреса –смещения, отсчитываемые от некоторой базовой точки («базовый адрес» жестко связан с адресом точки загрузки программы, т.е. при изменении последнего меняется на ту же величину). Таким образом, программист фактически не зависит от того, в какое место ОП будет помещена программа. В общем случае исполнительный адрес (вычисляемый ОС) определяется как сумма нескольких компонент:
A = B + D, где A – абсолютный (исполнительный адрес); B – значение базы; D – значение смещения. Во многих случаях возникает необходимость повторного прохождения некоторого участка программы, но при этом адреса, указанные в отдельных командах этого участка, должны быть изменены определенным образом. Поскольку написание адресов в тексте программы остается тем же, изменять их значение можно лишь косвенно, введя дополнительную компоненту в исполнительный адрес и изменяя ее содержание. Такая компонента, служащая для модификации адреса, носит название индекса. Таким образом, в общем случае структура исполнительного адреса имеет вид:
A = B + D + Х,
где Х – значение индекса. В нижеследующем показано формирование исполнительных адресов для некоторых команд ЭВМ типа IBM S/360/370. 1. CVB 13,8 (12) – Команда формата RX (преобразование десятичного формата в формат с ФТ) с использование явной адресации. Здесь: 8 – смещение, 13 и 12 - номера РОНов. Преобразуемое десятичное число находится в ОП по адресу, вычисляемому как сумма содержимого РОН 12 плюс смещение 8. Результат помещается в РОН 13. Следует заметить, что в этом формате опущен регистр базы. 2. AR 7, 3 – Команда формата RR с использованием явной адресации (сложение регистровое). Складывается содержимое регистров 7 и 3, результат помещается в РОН 7. 3. A 4, B1 – Команда формата RX с использованием базового регистра (неявная адресация). Если в программе задан в качестве базового регистра РОН 11, который загружен начальным значением 6, а значение счетчика адреса для имени В1 равно С8, тогда команда будет иметь вид:
4. BXH 6, 10, AS – Команда формата RS (переход по индексу). Если в качестве базового задан РОН-9, загружаемый начальным значением 6, а значение счетчика адреса для имени AS равно D4, то после трансляции команда будет иметь вид:
Учитывая, что по времени x86-совместимые ЭВМ появились позже, в них используются похожие способы адресации. Прежде чем переходить к способам адресации, применяемым в этих ЭВМ, напомним некоторые сведения о процессоре типа x86. Как уже отмечалось, одним из видов адресуемой памятью в этих ЭВМ является сегмент. Для обращения к сегменту используется специальный регистр, называемый сегментным регистром, в котором указывается номер используемого сегмента. Номер сегмента – это порядковый номер параграфа, с которого начинается используемый сегмент. Нумерация параграфов и сегментов в ОП ведется с нуля. В процессоре типа x86 можно использовать 6 типов сегментов, имеющих различное назначение и название: 1. Сегмент кода (Code Segment) является обязательным. В нем содержатся коды команд. Для его адресации существует специальный сегментный регистр кода (SEGcode), имеющий обозначение CS, в котором содержится начальный адрес сегмента кода. 2. Сегмент данных (Data Segment) содержит константы, переменные и рабочие области. Он адресуется с помощью сегментного регистра данных (SEGdata) и обозначается как DS. 3. Дополнительный сегмент данных (Extra Segment) также содержит константы, переменные и рабочие области и адресуется с помощью сегментного регистра дополнительных данных (ES), в котором указывается начальный адрес дополнительного сегмента данных. Возможно использование до трех дополнительных сегментов данных; дополнительные сегменты имеют обозначения ES,GSи FS. 4. Сегмент стека (Stack Segment) содержит временно сохраняемые данные, адреса точек возврата и другую информацию, которую необходимо временно сохранить для последующего использования. Он имеет обозначение SS и содержит начальный адрес сегмента стека. Для хранения операндов и результатов, выполнения операций в ЭВМ типа x86 используют регистры общего назначения(РОН), которые имеют обозначения: EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP. Все эти 32-разрядные регистры допускают адресацию и обработку отдельно старшего и младшего байтов. Например, AL - младший байт регистра AX, АН – старший байт регистра АХ. Перечисленные регистры имеют следующее назначение: EAX/AX/AH/AL – используется в основном при выполнении арифметических операций и играет роль аккумулятора; EBX/BX/BH/BL – служит в основном в качестве базового регистра при вычислении адреса операнда; в этом случае он по умолчанию используется в паре с регистром сегмента данных DS; ECX/CX/CH/CL – используется в качестве счетчика при выполнении некоторых команд; EDX/DX/DH/DL – регистр данных, он также содержит адрес порта в командах ввода-вывода и т.д.; ESI/SI – регистр индекса источника, используется в цепочечных операциях; EDI/DI – регистр индекса приемника, также используется в цепочечных операциях; ESP/SP – регистр указатель стека; EBP/BP – регистр указатель базы кадра стека, служит для организации произвольного доступа к данным внутри себя. Непосредственно адресуемое пространство (физическая память) определяется разрядностью адресной шины и аппаратными возможностями процессора, применяемого в ЭВМ. Рассмотрим способы адресации, применямые в так называемом реальном режиме работы x86-совместимой ЭВМ. В этом режиме работы разрядность адресного пространства составляет 20 бит. Физический адрес байта памяти формируется в виде суммы двух частей: физического адреса сегмента, в котором находится этот байт и внутрисегментного относительного адреса байта, отсчитываемого от начала сегмента. При этом 20-битный физический адрес получается путем умножения на 16 (сдвиг на 4 бита влево) номера сегмента (SEG), находящегося в специальном сегментном регистре. Относительный адрес, отсчитываемый от начала сегмента, представляет собой 16-битовое «смещение» (обозначается как ЕА или OFFSET). Иногда его называют «эффективный адрес». Таким образом, исполнительный физический адрес можно записать в следующем виде:
SEG∙16 + OFFSET Как уже отмечалось «смещение» - это относительный адрес внутри сегмента. Для кодового сегментаего называют указателем команд или счетчиком команд(Instruction Poiner – IP). Для сегментных данных смещение в общем случае может состоять из нескольких компонентов: базового адреса (В), переменного индекса (I) и постоянного индекса (D) . Как и в других классах ЭВМ, эти понятия имеют схожий смысл. База – некоторая точка отсчета, по отношению к которой можно определить местоположение других элементов (адрес первого или последнего элемента массива может служить базой для определения всех его остальных элементов). База задается как содержимое некоторого регистра, называемого базовым. Индекс – расстояние (сдвиг) между определяемым элементом и базой. Индекс может быть постоянным, если он указан в команде в виде константы (смещение в команде – Displacement), либо переменным, если задается как содержимое регистра, называемого индексным. Для стекового сегмента смещение представляет собой указатель вершины стека (Stack Pointer – SP). Таким образом, исполнительный физический адрес ОП (А) в общем случае для разных сегментов вычисляется по следующим правилам: 1. Для кодов команд Acode = SEGcode ∙ 16 + IP 2. Для данных Adata = SEGdata ∙ 16 + B + I + D 3. Для содержимого стека Astack = SEGstack ∙ 16 + SP 4. Для стекового кадра Astack = SEGstack ∙ 16 + BP + I + D BР – указатель базы в стеке.
Напомним, что базовый регистр для размещения данных в ОП имеет специальное обозначение ЕВХ/ВХ. Индексные регистры для приемника и источника имеют соответственно обозначения EDI/DI и ESI/SI. При записи адресов ОП в командах применяют два вида адресации : прямая и косвенная. При прямой адресации адрес операнда задается посредством идентификатора и смещения. При косвенной адресации адрес операнда формируется из содержимого регистров сегментов, базы и индекса. Всего используется 11 режимов адресации: 7 для адресации данных и 4 для указания адресов переходов. Эти режимы имеют следующие название: 1. Непосредственная адресация данных. 2. Прямая адресация данных. 3. Регистровая прямая адресация данных. 4. Регистровая косвенная адресация данных. 5. Регистровая относительная адресация данных. 6. Базовая индексная адресация данных. 7. Относительная базовая индексная адресация данных. 8. Внутрисегментная прямая адресация. 9. Внутрисегментная косвенная адресация. 10. Межсегментная прямая адресация. 11. Межсегментная косвенная адресация. Рассмотрим эти режимы адресации более подробно. 1. Непосредственный режим адресации. В этом способе адресации данные непосредственно указываются в команде в виде выражения, иногда называемого константным. Это выражение записывается с помощью констант, соединенных знаками операций. Числовая константа представляется в виде числа, записанного в той или иной системы счисления. Основание системы счисления указывается суффиксом: В (двоичная), О (восьмеричная), D (десятичная), Н (шестнадцатеричная). По умолчанию принята десятичная система счисления. Символьная константа записывается в виде цепочки символов, заключенных в апострофы. В качестве знаков арифметических операций можно использовать: +, -, * и / или MOD. Знаками логических операций являются: AND, OR, NOT, XOR, SHL, SHR. При формировании выражений допускается использование круглых скобок. Ниже приведены записи команд на языке ассемблера с использованием непосредственной адресации.
|


 ,
,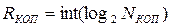 ,
,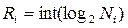
 ,
,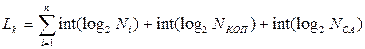
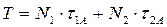 ,
, ,
,
 ØС2
ØС2 RB
RB 9
9 Ø С Е
Ø С Е