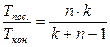| ПОЗНАВАТЕЛЬНОЕ Сила воли ведет к действию, а позитивные действия формируют позитивное отношение Как определить диапазон голоса - ваш вокал Игровые автоматы с быстрым выводом Как самому избавиться от обидчивости Противоречивые взгляды на качества, присущие мужчинам Вкуснейший "Салат из свеклы с чесноком" Натюрморт и его изобразительные возможности Применение, как принимать мумие? Мумие для волос, лица, при переломах, при кровотечении и т.д. Как научиться брать на себя ответственность Зачем нужны границы в отношениях с детьми? Световозвращающие элементы на детской одежде Как победить свой возраст? Восемь уникальных способов, которые помогут достичь долголетия Классификация ожирения по ИМТ (ВОЗ) Глава 3. Завет мужчины с женщиной
Оси и плоскости тела человека - Тело человека состоит из определенных топографических частей и участков, в которых расположены органы, мышцы, сосуды, нервы и т.д.
| Класс MISD - конвейерная обработка информации
Конвейерная обработка информации основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями, и выделении для каждой из них отдельного блока аппаратуры. Так, обработку любой машинной команды можно разделить на несколько этапов (несколько ступеней), организовав передачу данных от одного этапа к следующему. При этом конвейерную обработку можно использовать для совмещения этапов выполнения разных команд. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах. Как было уже отмечено, согласно классификации Флинна, ЭВМ и ВС, построенные по конвейерному принципу относятся к классу MISD – систем с множественным потоком команд и одиночным потоком данных. Конвейерная обработка может быть реализована в системе с одним процессором, разделенным на некоторое число последовательно соединенных операционных блоков, каждый из которых специализирован на выполнении строго определенного этапа арифметической или логической операции. Данный тип обработки данных иногда называетсяарифметико-магистральной обработкой. Очевидно, что идея конвейера может быть распространена и на выполнение команд. Подобного типа обработка при помощи конвейера команд носит название -командно-магистральная обработка. При применении конвейера команд цикл выполнения команды разбивается на ряд элементарных этапов, например: формирование адреса команды, выборка команды из памяти, расшифровка кода операции, формирование адреса операнда, выборка операнда из памяти и, наконец, выполнение самой арифметической или логической операции. В обрабатывающем устройстве предусматриваются блоки, которые независимо друг от друга и параллельно могут выполнять указанные этапы - из них и строится магистраль обработки. Арифметико-магистральная и командно-магистральная обработка относятся к классумикроконвейерной обработки. Разумеется, в вычислительных системах можно одновременно использовать и конвейер команд, и конвейер арифметических операций, и даже несколько параллельно работающих конвейеров команд и арифметических операций. В последнем случае может быть получена очень высокая производительность системы. Подробно особенности микроконвейерной обработки рассматриваются в курсе «Современные микропроцессоры», здесь же мы рассмотрим, как с помощью конвейерной обработки может быть организовано одновременное решение различных частей одной задачи. Рассмотрим данный способ обработки применительно к задачам, программа решения которых должна многократно повторяться. Разобьем некоторую программу А на одинаковые по времени реализации части - подпрограммы А1, А2, …, An, последовательное выполнение которых решает поставленную задачу. Теперь запрограммируем n процессоров P1, P2, …, Pn на решение этих подпрограмм и расположим их в цепочку-конвейер так, что результат работы i-го процессора является набором исходных данных для (i+1)-го процессора (см. рис. 5.10). Пусть X1, X2, …, Xk - исходные данные k задач, которые должны быть решены программой А k-кратным ее повторением, а R1, R2, …,Rn- результаты расчетов подзадач А1, А2, …, An. Будем последовательно подавать на вход цепочки процессоров исходные данные X1, X2, …, Xk с интервалом времени
Рис. 5.10. Конвейер вычислений на j-м шаге
Один процессор затратил бы на это время Tпос.=T×k. Таким образом, соотношение
определяет выигрыш, достигаемый в результате применения конвейера. Из этого выражения видно, что при фиксированном k ускорение обработки потока данных пропорционально числу n - длине конвейера, а при фиксированном n - длине обрабатываемой последовательности данных k. Рассмотренный тип обработки называется макроконвейерной обработкой и используется на практике только для создания специализированных ВС, постоянно решающих одну и ту же задачу на большом потоке данных.
Системы класса SIMD
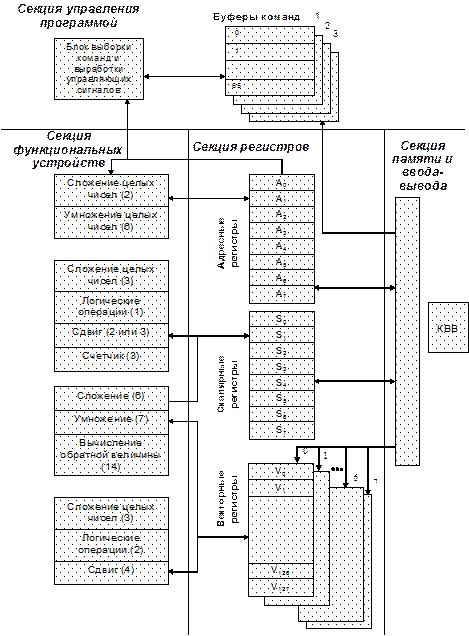
Векторные ВС Рассмотрим архитектуру векторной ВС на примере классических ЭВМ Cray, выпускавшихся с середины 70-х годов 20-го века компанией Cray Research. В большинстве своем данные ЭВМ представляли собой компьютеры, объединяющие несколько векторно-конвейерных процессоров, работающих над общей памятью. Оперативная память этих ВС разделяется всеми процессорами и секцией ввода-вывода. Для увеличения скорости выборки данных память разделена на множество банков, которые могут работать одновременно. Все процессоры имеют одинаковую структуру (рис. 5.11), которую рассмотрим подробнее. В состав процессора входят 3 секции: · функциональные устройства; · регистры; · управление программой.
Рис. 5.11. Схема векторно-конвейерного процессора Cray Функциональные устройства, работающие в режиме конвейера, разбиты на 4 группы: адресная, скалярная, операции с плавающей запятой, векторная. Число конвейерных ступеней (на рис. 5.11 это число указано в скобках после названия устройства) в каждом из функциональных устройств зависит от сложности операций и сравнительно невелико (от 1 до 14), что обеспечивает быстрое время загрузки конвейеров. Функциональные устройства Cray, играющие роль арифметико-логических преобразователей, не имеют непосредственной связи с главной памятью. Они имеют доступ только к быстрым операционным регистрам, из которых выбираются операнды и в которые помещаются результаты после выполнения соответствующих действий. Три группы операционных регистров, непосредственно связанные с арифметико-логическими устройствами, называются основными. К ним относятся восемь так называемых А-регистров. А-регистры связаны с двумя функциональными модулями, выполняющими сложение (вычитание) и умножение целых чисел. Эти операции используются главным образом для преобразования адресов, их базирования и индексирования. Они также используются для организации счетчиков циклов. В ряде случаев А-регистры можно использовать для выполнения арифметических операций над целыми числами. В следующую группу основных операционных регистров входят восемь 64-разрядных S-регистров, непосредственно связанных с функциональными устройствами выполнения арифметических действий со скалярными величинами, представленными с фиксированной и плавающей запятой. Особый интерес представляют восемь многоэлементных векторныхV-регистров, которые предназначены для хранения восьми операндов-векторов. Каждый такой операнд состоит из нескольких (до 128) элементов. В свою очередь каждый элемент представляет собой 64-разрядное слово - число с плавающей или фиксированной запятой. В системе команд ЭВМ предусмотрены специальные операции, в качестве операндов которых выступают многоэлементные векторы. Поскольку не во всех задачах требуется обрабатывать векторы полной размерности, специальный управляющий регистр процессора задает требуемую размерность (число элементов). Этот регистр программно управляем, что позволяет в процессе вычислений изменять размерность обрабатываемых векторов. Кроме того, в центральном процессоре предусмотрен регистр маски, с помощью которого можно блокировать выполнение арифметико-логических действий над некоторыми элементами вектора, т.е. осуществлять выборочные поэлементные действия. Все основные операции, выполняемые процессором (обращения в память, обработка команд и выполнение инструкций), являются конвейерными. Большинство функциональных устройств являются независимыми, поэтому несколько операций могут выполняться одновременно. Например, для операции A=(B+C)×D×E порядок выполнения может быть следующим (считаем, что все аргументы загружены в S-регистры). Генерируются три инструкции: умножение D и E, сложение B и C и умножение результатов двух предыдущих операций. Первые две операции выполняются одновременно, затем третья. Все основные операции, выполняемые процессором (обращения в память, обработка команд и выполнение инструкций), являются конвейерными. Большинство функциональных устройств являются независимыми, поэтому несколько операций могут выполняться одновременно. Например, для операции A=(B+C)×D×E порядок выполнения может быть следующим (считаем, что все аргументы загружены в S-регистры). Генерируются три инструкции: умножение D и E, сложение B и C и умножение результатов двух предыдущих операций. Первые две операции выполняются одновременно, затем третья. Векторные операции, использующие различные ФУ и регистры, также могут выполняться параллельно. Архитектура Cray позволяет использовать регистр результатов векторной операции в качестве входного регистра для последующей векторной операции, т.е. выход сразу подается на вход. Это называется зацеплением векторных операций. Вообще говоря, глубина зацепления может быть любой, например, чтение векторов, выполнение операции сложения, выполнение операции умножения, запись векторов. Зацепление функциональных устройств и конвейеризацию вычислений можно продемонстрировать на следующем примере. В вычислительных методах линейной алгебры часто встречается процедура, состоящая в том, что строку матрицы (все элементы строки матрицы) умножают на некоторую скалярную величину и затем вычитают из элементов другой строки. Поскольку функциональные устройства, выполняющие операции умножения и вычитания, могут работать одновременно, то данная вычислительная процедура может быть исполнена следующим образом. Первый элемент первого вектора умножается на скалярную величину, после чего начинается вычитание результата из первого элемента второго вектора. Пока происходит это вычитание, параллельно выполняется операция умножения скаляра на второй элемент первого вектора и т.д. Система команд ЭВМ семейства Cray прямо отражает регистровую структуру центрального процессора, своеобразие связи функциональных устройств с операционными регистрами и связи их с оперативной памятью. Команды машин Cray двух форматов: короткие команды - 16 разрядов и длинные - 32 разряда. Семь первых разрядов определяют код операции, затем следуют трехразрядные поля, определяющие соответственно номер регистра результата и номера регистров исходных операндов. В одном слове может размещаться до четырех команд короткого формата. Длинные команды могут начинаться в одном слове и продолжаться в следующем. Это позволяет плотно упаковывать команды в памяти машины и в какой-то степени ускоряет их выборку. Отметим, что защита памяти и система прерываний организованы так, что значительная доля работы по запоминанию информации для возврата, по организации процесса переключения с одной задачи на другую возлагается на операционную систему. Отсутствие достаточно развитых аппаратных средств динамического перераспределения памяти, упрощенный аппарат преобразования программных адресов в физические (аппаратное базирование) вполне допустимы в машинах, предназначенных для решения крупных научных задач. Этот режим «научных» вычислений характерен сравнительно редким появлением ситуации, требующих переключения с решения одной задачи на другую. Это в свою очередь позволяет по-иному реализовать защиту и прерывания, не заботясь о быстром аппаратном их выполнении. Для межпроцессорного взаимодействия служит специальная секция, которая содержит разделяемые регистры и семафоры, предназначенные для передачи данных и управляющей информации между процессорами.
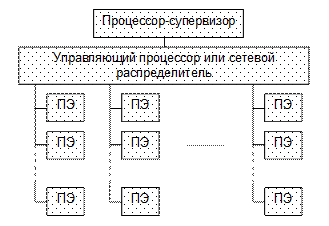
Матричные системы Основной особенностью матричных и векторных операций является то, что одна и та же команда должна выполнятся одновременно над большой совокупностью связанных между собой некоторым образом данных, т.е. реализуетсясинхронный параллельный вычислительный процесс. В подобном случае достаточно иметь одно устройство управления, которое могло бы дешифровать одиночный поток команд и вырабатывать управляющие сигналы для некоторой совокупности (матрицы, вектора) процессорных элементов (ПЭ) – некоторых простых (элементарных) процессоров. Организация систем этого типа следующая: общее управляющее устройство, генерирующее поток команд, и большое число ПЭ, работающих параллельно и обрабатывающих каждое свой поток данных. ПЭ связываются друг с другом определенным образом, причем характер связей может быть различным, так же как и характер взаимодействия ПЭ. Схематическое изображение конфигурации матричного процессора приведено на рис. 5.12. Отдельные процессорные элементы (элементарные процессоры) не являются законченными центральными процессорами и не могут работать самостоятельно. Единственная степень свободы ПЭ, работающего в матричной системе, состоит в том, что он может выполнять или не выполнять некоторую частную команду. Сигналы, реализующие эту возможность, вырабатываются и распределяются специальным управляющим процессором. Первым большим достижением в этой области была разработка системы SOLOMON (США), за которой последовала система SOLOMON-II. Проект системы SOLOMON не был реализован, система оказалась нежизнеспособной вследствие громоздкости, недостаточной гибкости и эффективности. Однако идеи, заложенные в ней, получили развитие в системе ILLIAC-IV, разработанной Иллинойским университетом и изготовленной фирмой Burroughs.
Рис. 5.12. Обобщенная схема матричной ВС
По первоначальному проекту (рис. 5.13) система ILLIAC-IV должна была включать в себя 256 ПЭ, разбитых на 4 группы – квадранты, каждый из которых должен управляться специальным процессором (УП). Кроме ПЭ и УП ВС содержала также внешнюю память и оборудование ввода-вывода. Управление всей системой предполагалось осуществлять с помощью центрального управляющего процессора (ЦУП). Однако реализовать этот замысел не удалось из-за возникших технологических трудностей при создании интегральных схем, ОЗУ и удорожания всего проекта почти в два раза. В результате с опозданием на два года (в 1971 г.) система была создана в составе одного квадранта и одного УП и с начала 1974 г. введена в эксплуатацию. Ранее предполагалось получить на этой системе производительность примерно 1 GFLOPS, однако реально было достигнуто лишь 200 MFLOPS. Тем не менее, этого оказалось достаточно, чтобы система в течение ряда лет считалась самой высокопроизводительной в мире.
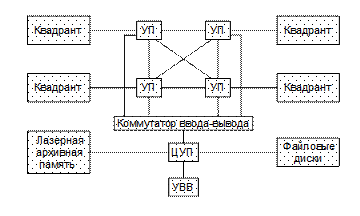
Рис. 5.13. Система ILLIАС-IV (проект) В каждом квадранте (рис. 5.14) 64 ПЭ образовывали матрицу размером 8x8. Связь с внешней средой имели все ПЭ без исключения. Реально действовавшая система ILLIAC-IV состояла из двух частей: центральной с устройством управления и 64 ПЭ, а также подсистемы ввода–вывода, включавшей в себя универсальную ЭВМ В-6700, файловые диски и лазерную архивную память большой емкости. Каждый ПЭ состоял из 64-разрядного процессора и ОЗУ. Процессор выполнял универсальный набор операций, достигая в среднем производительности 3 MFLOPS. Емкость ОЗУ каждого ПЭ составляла 2048 64-разрядных слов, при длительности цикла памяти 350 нс. Память была выполнена на интегральных схемах. Каждый процессор имел счетчик адресов и индексный регистр. Конечный адрес мог формироваться как сумма трех составляющих: адреса, содержавшегося в команде для данного ПЭ, кода, содержавшегося в центральном индексном регистре УУ, и кода, содержавшегося в собственном индексном регистре. Каждый процессор кроме индексного регистра имел в своем составе пять программно-адресуемых регистров: накапливающий сумматор, регистр для операндов, регистр пересылок (для передач информации от одного ПЭ к другому), буферный регистр на одно слово и 8-разрядный регистр управления состоянием ПЭ. В зависимости от содержимого регистра управления определялась активность или пассивность ПЭ.
Рис. 5.14. Квадрант системы ILLIAC-IV Если вычисления не требовали полной разрядности, то процессор мог быть разбит на два 32-разрядных подпроцессора или даже восемь 8-разрядных. Это позволяло в случае необходимости обрабатывать векторные операнды из 64, 2x64=128 и 8x64=512 элементов. Как видно из рис. 5.14, каждый i-й ПЭ связан с четырьмя другими: (i‑1)‑,(i+1)‑,(i+8)‑ и (i-8)-м. При такой связи передача данных между любыми двумя ПЭ осуществляется не более, чем за 7 шагов, а среднее число шагов равно 4. По шине состояния ПЭ могли передавать сигналы о состоянии в УУ. Оперативное ЗУ каждого ПЭ было связано со своим процессором, устройством управления центральной частью и подсистемой ввода-вывода, включавшей в себя универсальную ЭВМ В-6700. Машина В-6700 выполняла и различные другие функции: трансляции программ, управления запросами на ресурсы, предварительной обработки информации и т. д. Следует подчеркнуть, что сверхвысокая производительность системы достигалась только на определенных типах задач, таких, например, как операции над матрицами, быстрое преобразование Фурье, линейное программирование, обработка сигналов, т.е. задач с достаточно крупным зерном параллелизма. Необходимо отметить также и то, что разработка высокопроизводительных программ для системы ILLIAC-IV являлась весьма трудоемким занятием. Для упрощения этой работы были разработаны специальные алгоритмические языки.
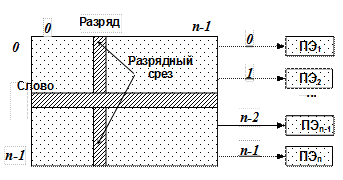
Ассоциативные системы К числу систем класса SIMD относятся ассоциативные системы. Эти системы, как и матричные, характеризуются большим числом операционных устройств, способных одновременно, по командам одного управляющего устройства, вести обработку нескольких потоков данных. Но эти системы существенно отличаются от матричных способами формирования потоков данных. В ассоциативных системах информация на обработку поступает отассоциативных запоминающих устройств (АЗУ). Напомним, что АЗУ характеризуются тем, что информация из них выбирается не по определенному адресу, а по ее содержанию, задаваемому в виде признака сравнения.Запоминающие элементы АЗУ, в отличие от элементов адресуемых ЗУ, способны не только хранить информацию, но и выполнять определенные логические функции. АЗУ позволяют осуществить поиск как по равенству содержимого ячейки заданному признаку сравнения, так и по условиям «больше (меньше)», «больше или равно (меньше или равно)». Отмеченные выше свойства АЗУ характеризуют их преимущества для обработки информации. Формирование нескольких потоков идентичной информации с помощью АЗУ осуществляется быстро и просто, а с большим числом операционных элементов можно создавать высокопроизводительные системы. Надо учитывать еще и то, что на основе ассоциативной памяти легко реализуется изменение места и порядка расположения информации. Благодаря этому АЗУ является эффективным средством формирования наборов данных. Целый ряд задач, таких, как обработка радиолокационной информации, распознавание образов, обработка различных снимков и других задач с матричной структурой данных, эффективно решается ассоциативными системами. При этом программирование таких задач для ассоциативных систем может быть проще, чем для традиционных ВС. Все сказанное является предпосылкой достижения на основе ассоциативного принципа обращения к информационным словам высокой степени параллельности их обработки, когда одна операция выполняется одновременно над всем множеством содержащихся в выделенном поле ассоциативной памяти слов. При этом в простейшем случае обрабатывающее устройство -ассоциативный процессор - состоит из ассоциативной памяти и процессорных элементов (ПЭ), реализующих арифметическую и логическую обработку информации. Достижение наивысшей степени производительности обработки возможно, когда число ПЭ соответствует числу обрабатываемых слов. При этом, если они обрабатываются поразрядно-последовательно, то в каждый момент времени ПЭ обрабатывают так называемый «разрядный срез» всех слов ассоциативной памяти. На рис. 5.15 изображена схема n-разрядной ассоциативной ВС.
Рис. 5.15. Структура n-разрядной ассоциативной ВС
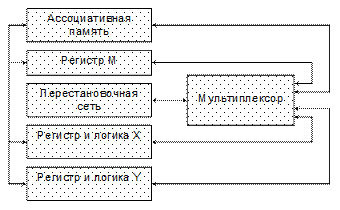
Рассмотрим более подробно структуру ассоциативной ВС на примере системы STARAN (США), являющейся наиболее характерным представителем систем данного класса. Ассоциативная память в ВС STARAN имела многомерный доступ, т.е. в нее можно было обратиться как поразрядно, так и пословно. Операционные процессорные элементы были предусмотрены для каждого слова памяти. Кроме этого, система обладала уникальной схемой перестановок для перегруппировки данных в памяти. Основным элементом системы являлась многомерная ассоциативная матрица – ассоциативный модуль (АМ), который представлял собой квадрат из 256 разрядов на 256 слов, т.е. содержал 65536 бит данных. Для обработки информации предназначались 256 процессорных элементов, работавших одновременно, по одной команде, выдаваемой устройством управления. Сразу по одной команде обрабатывались все выбранные по определенным признакам из памяти слова.
Рис. 5.16. Схема ассоциативной ВС STARAN Модуль процессорных элементов состоял из трех 256-разрядных регистров - M, X и Y. В состав каждого элементарного процессора входило по одному разряду из названных регистров. Регистр маски (M) позволял маскировать элементы 256-разрядных кодов. Регистры X, Y и связанная с ними логика были предназначены для выполнения логических операций над двумя переменными. Мультиплексор обеспечивал поочередное использование перестановочной сети с различными устройствами модуля: памятью, регистрами, магистралями ввода-вывода. Перестановочная сетьиграла важную роль при реализации операций перестроения данных в ассоциативной памяти. Она осуществляла передачу информации из одного ПЭ в другой за счет управляемой перестановки разрядов при передаче слов через сеть. Многократной передачей данных через перестановочную сеть можно было добиться сложных их перестроений как в вертикальном, так и в горизонтальном направлении. Базовая конфигурация системы STARAN содержала один AM. Однако число этих модулей могло варьироваться в системе от 1 до 32. При максимальной комплектации acсоциативной обработке в системе могло подвергаться 256 Кбайт информации. Устройство управления ассоциативными модулями организовывало выполнение операций над данными по командам, хранившимся в управляющей памяти. Можно было выбирать несколько рабочих подмножеств из общего множества данных, хранимых в AM, и выполнять над этими подсистемами операции, не затрагивая остальную информацию. К системе подключался последовательный контроллер (однопроцессорная ЭВМ типа PDP-11). Данная ЭВМ обеспечивала работу в режиме трансляции и отладки программ; первоначальную загрузку управляющей памяти, связь между оператором и системой; управление программами обработки прерываний по ошибкам, а также программами технической диагностики обслуживания.
Системы класса MIMD
|


 , где Т - общее время решения одной задачи, если бы она выполнялась на одном процессоре (тогда
, где Т - общее время решения одной задачи, если бы она выполнялась на одном процессоре (тогда