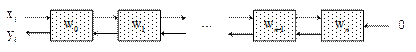| ПОЗНАВАТЕЛЬНОЕ Сила воли ведет к действию, а позитивные действия формируют позитивное отношение Как определить диапазон голоса - ваш вокал Игровые автоматы с быстрым выводом Как самому избавиться от обидчивости Противоречивые взгляды на качества, присущие мужчинам Вкуснейший "Салат из свеклы с чесноком" Натюрморт и его изобразительные возможности Применение, как принимать мумие? Мумие для волос, лица, при переломах, при кровотечении и т.д. Как научиться брать на себя ответственность Зачем нужны границы в отношениях с детьми? Световозвращающие элементы на детской одежде Как победить свой возраст? Восемь уникальных способов, которые помогут достичь долголетия Классификация ожирения по ИМТ (ВОЗ) Глава 3. Завет мужчины с женщиной
Оси и плоскости тела человека - Тело человека состоит из определенных топографических частей и участков, в которых расположены органы, мышцы, сосуды, нервы и т.д.
| Вычислительные системы, управляемые потоком данных
Рассмотренные до сего момента параллельные ЭВМ и ВС имели так называемую традиционную архитектуру, которая опирается на два основополагающих взаимосвязанных принципа. 1. Процессоры параллельной ВС имеют фон-неймановскую архитектуру, предусматривающую хранение программного кода и данных в одной памяти и последовательное выполнение команд. Адрес следующей команды, которую процессор должен выполнить, определяется значениемпрограммного счетчика. Фактически порядок выполнения команд задается последовательностью значений программного счетчика. Команда выполняется после того, как выполнена предшествующая ей команда последовательности. При этом процессор считает каждую очередную машинную команду полностью готовой к исполнению и независимой от других команд выполняемой программы. Задача обеспечения действительной готовности команды, т.е. правильности кода операции и операндов, целиком возлагается на программиста. 2. Построениесхемы параллелизма (распределение вычислений и данных по процессорам и организация обмена данными) в традиционных параллельных ВС также целиком возлагается на программиста. Как уже отмечалось, та или иная парадигма или модель параллельного программирования представляет собой не что иное, как способ записи уже готовой схемы параллелизма. Для достижения близкой к пиковой производительности в традиционных ВС от программиста и транслятора фактически требуется соблюдение идеальных условий. На вход каждого из процессоров системы должна поступать последовательность команд, обеспечивающая постоянную полную загрузку функциональных устройств процессора. Как известно, полной загрузки всех ФУ процессора трудно добиться даже в ЭВМ последовательного типа. В параллельных ВС простои неизбежны, во-первых, из-за особенностей алгоритма (см. закон Амдала), во-вторых, из-за сложности балансировки загрузки процессоров. В самом деле, с одной стороны, распределение вычислений и данных по процессорам, равно и как организация информационных обменов и синхронизация, определяется человеком. С другой стороны, продолжительность каждого вычислительного процесса зависит от величин входных обрабатываемых данных, получаемых в процессе вычислений, и не всегда может быть заранее вычислена, что и приводит к неизбежным простоям оборудования и снижению производительности. Заметим, что традиционные параллельные ВС часто используют экстенсивный путь развития. Производительность отдельных процессоров увеличивается за счет более плотной упаковки транзисторов на кристалле и повышения тактовой частоты, а производительность всей системы в целом – за счет увеличения числа процессоров. Очевидно, ни то, ни другое никоим образом не решает обозначенную проблему простоя оборудования.
Рис. 5.31. Граф потока данных (потоковый граф) В то же время, как показывают исследования, очень многие задачи обладают так называемым скрытым параллелизмом, определение схемы которого для программиста-человека является практически неразрешимой задачей. Применение моделей программирования для традиционных архитектур приводит к тому, что скрытый параллелизм задачи не только не выявляется, но даже полностью вырождается. Проиллюстрируем это на следующем примере. Для описания вычислительного процесса будем использовать так называемыйграф потоков данных(потоковый граф). Этот граф состоит из вершин, отображающих операции (сложение, деление, умножение, сравнение и т.п.) и дуг, показывающих потоки данных между теми вершинами графа, которые они соединяют. Пусть некоторый вычислительный процесс может быть представлен графом потока данных, изображенным на рис. 5.31. Граф потока данных на рис. 5.31 фактически можно считать разновидностью ярусно-параллельной формы программы. Вершины графа – арифметические операции – распределены по уровням a,b,…g. Каждая вершина имеет свой идентификатор, состоящий из буквы уровня и номера вершины на уровне. На рис. 5.31 хорошо виден скрытый параллелизм алгоритма - вершины-операции одного уровня являются независимыми и могут выполняться параллельно. При выполнении данного вычислительного процесса на ЭВМ традиционной архитектуры мы можем получить примерно следующий порядок выполнения операций (рис. 5.32, показано серой линией).
Рис. 5.32. Выполнение алгоритма на традиционной ЭВМ Очевидно, изображенный порядок выполнения операций сводит на нет весь скрытый параллелизм алгоритма. Теперь представим, что изображенный вычислительный процесс представляет собой одну ветвь параллельной программы. Каждая из ветвей исполняется на отдельном процессоре традиционной архитектуры. Получается парадоксальная ситуация. Сначала программирование алгоритма для фон-неймановской ЭВМ уничтожает его скрытый параллелизм, а затем программистом прилагаются значительные усилия для распараллеливания получившейся программы: выделяются ветви из последовательной программы, распределяются данные по ветвям и организуется взаимодействие ветвей. Стремление устранить указанное противоречие и привело к идее создания ВС, управляемых потоком данных, – потоковых архитектур. Основные цели построения подобных систем следующие: 1. Человек (программист) должен быть исключен из распределения вычислительных процессов по вычислительным ресурсам системы, а также решения задачи синхронизации параллельных процессов по данным. 2. Предельное распараллеливание вычислительных процессов и синхронизация их по данным должна выполняться только на аппаратном уровне в динамике вычислений. В соответствии с этими целями и был сформулирован основной принцип потоковой обработки – команда выполняется, когда становятся доступными ее операнды. ВС, построенные по указанному принципу, называют потоковыми или управляемые потоком данных (dataflow, data driven), в отличие от традиционных, управляемых потоком команд. В потоковых ВС последовательность выполнения команд задается непосредственно графом потока данных. Вершины-операции выполняются, когда по дугам в вершину поступили все необходимые операнды. Обычно вершина-операция требует одного или двух операндов, а для условных операций необходимо наличие входного логического значения. При выполнении операции могут быть сформированы один или два результата. Таким образом, у каждой вершины может быть до трех входящих и одна или две выходящих дуги. При поступлении в вершину всех операндов активируется соответствующая операция, что иногда называют инициированием вершины. После выполнения операции результаты передаются по соответствующим дугам к ожидающим их вершинам. Процесс повторяется, пока не будут инициированы все вершины и получен окончательный результат. Очевидно, что одновременно может быть инициировано несколько вершин, что позволяет автоматически выявить скрытый параллелизм алгоритма. Выполнение графа потока данных реализует параллельность вычислительных процессов, заданной программой, и исключает конфликтные ситуации по данным. Фактически в потоковой ВС исключается обычная оперативная память, запись и считывание данных из которой осуществляется операторами присваивания. К сожалению, при практической реализации потоковых архитектур возникают сложности, из-за которых на сегодняшний день пока не удалось построить эффективно работающей ВС. Во-первых, блок управления потоковой ВС должен быть способен выявлять готовые к исполнению команды. При этом для того, чтобы производительность потоковой ВС превышала или была сопоставима с производительностью традиционной ЭВМ, время поиска готовых команд не должно сильно превосходить времени выборки очередной команды в традиционной ЭВМ. Очевидно, реализовать столь быстрый поиск непросто. Во-вторых, одновременное исполнение независимых команд потокового графа требует наличие многочисленных параллельно работающих функциональных устройств. Наконец, в-третьих, при наличии большого числа ФУ для поддержания высокой эффективности потребуется организация высокоскоростной широкополосной магистрали данных между ФУ и оперативной памятью. Практические попытки разработок потоковых ВС показывают, что одновременное соблюдение всех трех перечисленных условий чрезвычайно затруднено. Тем не менее, теоретические преимущества потоковой обработки перед традиционными архитектурами настолько очевидны, что ученые и инженеры не оставляют попыток практических разработок потоковых ВС. В России подобными исследованиями активно занимается Институт проблем информатики РАН под руководством академика В.С. Бурцева. Коллектив ИПИ РАН предложил настолько удачную архитектуру потоковой ВС, что на ее примере мы проиллюстрируем основные принципы построения систем потоковой обработки.
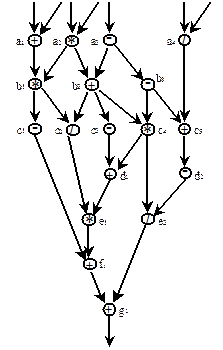
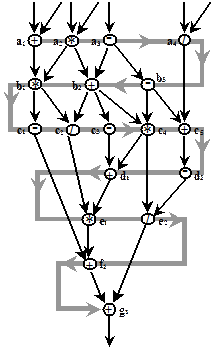
Рис. 5.33. Фрагмент потокового графа
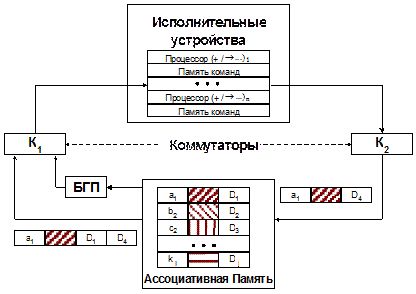
Рассмотрим фрагмент графа потока данных (рис. 5.33). Операторы программы представлены вершинами графа, каждая вершина имеет уникальный идентификатор (буква и индекс в кружке), однозначно определяющий оператор программы. Идентификатор вершины (ai, biи т.д.) является фактически адресом соответствующего оператора. Данные, поступающие в вершину являются входными операндами для соответствующей вершине команды. Каждая команда состоит из кода операции (сложение, деление, умножение и т.п.) и идентификаторов (адресов) вершин, куда необходимо направить результат. Таким образом, результат выполнения любой команды является операндом для одной или нескольких других команд. Нетрудно видеть, что каждое данное (операнд), передаваемое по дугам потокового графа содержит идентификатор (адрес) той вершины, куда оно направляется. Для того, чтобы различить данные, направляющиеся к одной вершине, но относящиеся к разным итерациям цикла или разным подпрограммам, каждому операнду приписывается определенный «цвет». Для инициации вершины и выполнения команды необходимо, чтобы в нее поступили операнды одного «цвета». На рис. 5.33 видно, что к вершинам a2 и a3 поступили данные от разных итераций (подпрограмм), имеющие разные «цвета». Архитектура потоковой ВС представлена на рис. 5.34. Работа такой системы сводится к следующему. Выходящие из исполнительных устройств данные – результаты выполненных операций – в свою очередь являются операндами для последующих операций. Каждое выходное данное содержит указатель на следующий оператор (вершину потокового графа). Ассоциативная память (АП) объединяет данные, относящиеся к одному и тому же оператору (вершине графа). Если парного данного нет в АП, происходит его запись на свободное место АП. Если парное данное есть, то происходит считывание этого данного со стиранием его в АП и формирование пары данных, направленных к одному и тому же оператору, которая выдается на исполнительное устройство. Для объединения данных, имеющих единый «цвет» и относящихся к одной и той же вершине потокового графа, АП должна объединять данные по «цвету» и идентификатору вершины потокового графа (адресу). Если пара по этим признакам найдена, АП выполняет ранее описанный алгоритм. В том случае, если парный операнд не находится в памяти, АП производит запись операнда на любое свободное место. Применение ассоциативной памяти в данной архитектуре способствует решению многих проблем, тормозящих развитие принципов управления потоком данных.
Рис. 5.34. Архитектура ВС, управляемой потоком данных Фактически АП берет на себя функции управления вычислительным процессом. При этом, в отличие от традиционных ВС, где устройство управления нерегулярно, АП делает вычислительную систему чрезвычайно регулярной структурой, тем самым значительно улучшая технологичность изготовления потокового процессора. Однако АП является и самым узким местом в вычислительной системе. Дело в том, что скорость работы АП обратно пропорциональна её объёму. Малый объем АП не позволяет организовать массовые вычисления, а большой объем значительно снижает скорость выборки готовых команд. Для сохранения высокой скорости выборки при больших объемах АП применяется принцип модульного построения, для реализации которого вводятся два коммутирующих устройства. Коммутатор К1 распределяет выходящие из модулей АП готовые команды по свободным исполнительным устройствам. Коммутатор К2 распределяет выходящие из исполнительных устройств результаты по модулям АП. Если имеются N исполнительных устройств и N модулей АП, то коммутаторы К1 и К2 являются коммутаторами NxN. Для эффективного распределения и поиска данных по модулям АП используются специальные хеш-функции. Готовые к исполнению команды поступают в буфер готовых пар (БГП). Таким образом, к особенностям рассмотренной архитектуры, определяющим ее преимущества перед традиционным подходом, относятся следующие. 1. На аппаратном уровне реализуется практически полный параллелизм вычислительных процессов выполняемой задачи, что позволяет достигать очень высокой производительности. Ассоциативная память автоматически определяет все имеющиеся на данный момент времени параллельные процессы и передает их в ИУ на исполнение, одновременно осуществляя синхронизацию по данным. 2. Программист исключен из процесса распределения вычислений, которое осуществляется автоматически в процессе прохождения вычислительного процесса, что обеспечивает высокий коэффициент использования системы. 3. Обеспечивается высокая структурная надежность и технологичность системы. Выход из строя или повреждение нескольких исполнительных устройств или модулей АП не приводит к нарушению функционирования системы. Самое нерегулярное и сложное по технологии устройство управления процессором заменяется регулярной системой АП, устойчивой к технологическим дефектам. 4. Конвейеризация вычислительного процесса за счет работы ассоциативной памяти позволяет нивелировать временные задержки в логических схемах. Из АП на исполнительные устройства поступают не связанные между собой пары данных для исполнения операций. Это позволяет строить систему по конвейерному принципу, исключая временные задержки из вычислительного процесса. 5. АП берет на себя функцию адресной арифметики и целый ряд других функций, управленческого характера, существенно упрощая написание программ и повышая производительность процессоров. 6. Потоковый процессор, при работе в масштабе реального времени практически не нуждается в традиционном регистре прерываний, реагируя практически мгновенно на сигналы, приходящие в масштабе реального времени. Эта структура не требует затрат процессорного времени на ожидание прерывания. Переход к необходимой программе обработки сигнала, приходящего в масштабе реального времени происходит через ячейку АП, в которую направляется этот сигнал. В ИПИ РАН был изготовлен макет рассмотренной потоковой ВС, а также были разработаны ее программный эмулятор и язык программирования вместе с транслятором. Эмулятор позволяет запускать оттранслированные программы, оценивать время их исполнения и эффективность использования ресурсов. Результаты проведенных макетных экспериментов выявили основные преимущества потоковой обработки. Во-первых, программы для потоковой ВС получаются очень компактными (например, решение известной задачи о восьми ферзях реализуется двумя десятками машинных команд). Во-вторых, потоковая ВС, как и ожидалось, позволяет автоматически выявлять скрытый параллелизм задач и эффективно (близко к 100%) использовать вычислительные ресурсы. В тоже время широкому распространению потоковых систем мешает ряд факторов. Во-первых, отсутствует отлаженная технология их промышленного производства, существующие макеты не могут рассматриваться даже как предсерийные образцы. Во-вторых, потоковые ВС не являются универсальными – с их помощью нельзя решить произвольно взятую задачу, например, разработать офисное приложение. В-третьих, для использования потоковых ВС необходимо не только полностью переписать программы на новом языке программирования, но и пересмотреть традиционные алгоритмы решения задач для получения возможности их решения на потоковой ВС.
Систолические массивы Систолические архитектуры (их чаще называют систолическими массивами - СМ) представляют собой множество процессоров (в терминологии систолических архитектур они называются процессорными элементами – ПЭ), объединенных регулярным образом. Топология объединения может быть любой, хотя чаще всего используются «линейка» и «решетка». Обращение к памяти может осуществляться только через определенные ПЭ на границе массива (рис. 5.34). Выборка операндов из памяти и передача данных по массиву и вычисления осуществляются в одном и том же темпе по тактам синхронизации. Каждый из ПЭ массива «знает», от кого он должен принять входные данные и кому должен отдать результаты на каждом шаге счета. При этом каждый ПЭ на каждом шаге вычислений выполняет небольшую инвариантную последовательность действий.
Рис. 5.35. Обобщенная структура систолического массива Таким образом, систолический массив - это вычислительная сеть, которая производит ритмические вычисления и передачу данных по системе, и обладает следующими характеристиками: 1. Синхронность. Данные вычисляются ритмично (при глобальном тактировании) и пропускаются по сети. 2. Модульность и регулярность. Массив содержит модульные ПЭ с однородными связями. Вычислительная сеть может неограниченно расширяться. 3. Пространственная локальность и временная локальность. Систолические массивы характеризуются локально связанной структурой межсоединений, т.е. пространственной локальностью. В структуре существует распределенная задержка (как минимум единичной длительности), в течение которой могут быть завершены приём, обработка и выдача сигнала от одного ПЭ к другому. Данная задержка определяет временную локальность. 4. Конвейеризуемость, определяющее ускорение выполнения, прямо пропорциональное числу ПЭ. Рассмотрим пример систолического массива, вычисляющего свертку числовой последовательности xi, i Î {0,…,n}. Выходная числовая последовательность yi, i Î {0,…,n}определяется формулой
где wj определяет весовой коэффициент свертки. Систолический массив для свертки указанного вида будет иметь вид, показанный на рис. 5.36.
Рис. 5.36. Систолический массив для вычисления свертки Каждый ПЭ получает две входных величины ain и bin, на каждом такте работы СМ вырабатывает две выходных величины aout и bout по формулам, показанным на рис. 5.37.
Рис. 5.37. Элемент систолического массива для вычисления свертки
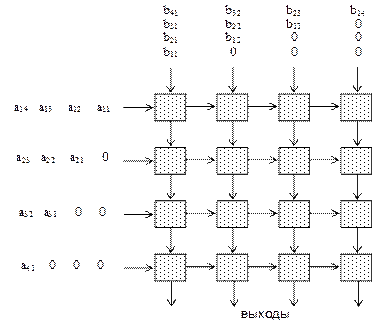
На рис. 5.38 показан пример систолического массива для умножения матриц. Рассмотрим основные свойства систолических архитектур. 1. Простота и регулярность схемы. Систолический массив легко реализуется в виде СБИС или ПЛИС. 2. Параллелизм и связь. Параллелизм определяется алгоритмом, связи – локальные и регулярные, что опять-таки способствует дешевой и простой реализации. 3. Сбалансированность вычислений с вводом-выводом. Следует отметить, что в систолических архитектурах под операциями ввода-вывода понимаются информационные обмены между граничными ПЭ массива и оперативной памятью. Конструктивно систолические массивы реализуются либо в виде заказных СБИС, либо с помощью ПЛИС в виде дополнительного вычислителя к основной универсальной ЭВМ, оперативная память которой используется для получения СМ исходных данных и записи результатов. Конечная цель разработки СМ – достижение скорости вычислений, согласованной с шириной полосы ввода-вывода основной ЭВМ. Систолические массивы используются для аппаратной реализации какого-либо алгоритма. Естественно, что перенастройка уже построенного массива под другой алгоритм невозможна. Однако за счет потери универсальности достигаются высокие показатели производительности на данном алгоритме.
Рис. 5.38. Систолический массив для умножения матриц Построение систолического массива предполагает проведение систолизации - отображение алгоритма в систолический массив. Данное отображение проводится в три этапа: 1. На первом этапе осуществляется построение графа зависимостей (ГЗ). Рассматривается соответствующее пространственно-временное индексное пространство, в качестве вершин выступают элементарные шаги алгоритма, для отображения зависимости между шагами используются дуги графа. 2. Следующим этапом является построение графа потока сигналов (ГПС). Вершины ГЗ, соответствующие шагам алгоритма преобразуются в узлы обработки, зависимости – в ребра связи. В отличие от ГЗ, в ГПС вводятся задержки, учитывающие временную локальность будущего систолического массива. 3. Последним этапом является собственно систолизация – отображение графа потока сигналов в систолический массив. Существует достаточно широкий класс алгоритмов, чье решение на систолических массивах весьма эффективно и целесообразно. К данным задачам относятся: · алгебраические операции с матрицами; · алгоритмы сортировки; · задачи динамического и математического программирования; · поиск глобального оптимума сложных математических функций; · нейронные алгоритмы. Рассмотрим основные показатели эффективности систолического массива, определяющие качество решения им поставленной задачи. 1. Время вычислений Т: интервал между началом первого вычисления и окончанием последнего. Время начала первого вычисления отсчитывается с момента поступления на вход массива первой входной величины. Соответственно, время окончания вычислений определяется записью последней выходной величины в оперативную память. 2. Конвейерный такт α: интервал между двумя последовательными вычислениями в процессорном элементе. Фактически определяется тактом синхронизации массива. 3. Блочный конвейерный такт β: интервал между началом двух последовательных задач, выполняемых в СМ. При выполнении определенной задачи (например, перемножая две конкретные матрицы), в силу конвейерности вычислений, часть ПЭ освобождается раньше других и может начать выполнять следующую задачу (в нашем примере – умножать следующие две матрицы). Отличие блочного конвейерного такта от времени вычислений определяется длиной конвейера. 4. Размер массива – число ПЭ. 5. Число каналов ввода-вывода – фактически число портов доступа к оперативной памяти основной ЭВМ. Систолические массивы применяются для решения задач трех типов: 1. Решение одной задачи с конечным потоком данных; 2. Решение одной задачи с бесконечным потоком данных; 3. Решение множества задач. Таким образом, основной принцип систолической разработки можно сформулировать, как достижение массового параллелизма при минимальных затратах на коммуникации. При этом применение систолических архитектур ограничено специальным классом алгоритмов, использующих регулярные и локальные структуры данных.
Вопросы для самоконтроля 1. Что такое параллельная обработка информации? 2. Какие уровни параллелизма Вы знаете? 3. Охарактеризуйте типы параллельной обработки. 4. Как записывается ярусно-параллельная форма программы? 5. Выведите закон Амдала и его следствие. 6. Как различает параллельные ВС классификация Флинна? 7. Сравните классификации Флинна и Фенга. Перечислите их достоинства и недостатки. 8. Поясните современную классификацию параллельных ВС. 9. Сопоставьте основные этапы развития параллелизма в архитектуре ЭВМ в мировой и отечественной практике. 10. Что такое схема параллелизма? 11. Какие Вы знаете парадигмы и модели параллельного программирования? 12. Перечислите средства параллельного программирования и дайте им краткую характеристику. 13. Что препятствует векторизации программ? 14. Какие существуют способы устранения зависимостей при векторизации программ? 15. Как вычисляется ускорение при макроконвейерной обработке? 16. Как и за счет чего происходит зацепление функциональных устройств в векторно-конвейерном процессоре? 17. Чем отличаются матричные ВС от векторных? 18. Назовите предпосылки достижения высокой производительности при ассоциативной обработке. 19. Поясните схему ассоциативного процессора. 20. Что собой представляет MIMD-система? 21. Приведите основные характеристики коммуникационных сред MIMD-систем. 22. Как устроен простой коммутатор с пространственным разделением? 23. Как осуществляется построение составного коммутатора? 24. Сравните преимущества и недостатки коммутатора Клоза и дельта-сетей. 25. Постройте коммутатор Клоза размером 20x20. 26. Постройте дельта-сеть размером 27x27. 27. Какими характеристиками обладает граф межмодульных связей распределенного составного коммутатора? 28. Из-за чего могут образовываться дедлоки в коммутаторах? 29. В чем состоит маршрутизация с ациклическим графом зависимостей? 30. В чем состоит маршрутизация по числу пройденных перегонов? 31. Чем отличаются SMP- и NUMA-системы? 32. Назовите подходы и способы поддержания когерентности в ВС с общей памятью. 33. Поясните диаграмму переходов состояний протокола MESI. 34. Как осуществляется запись строки в удаленном ВМ согласно протоколу DASH? 35. Какие архитектурные особенности имели отечественные MPP-системы МВС-100x? 36. Чем отличаются кластерные ВС от массово-параллельных? 37. В чем состоят преимущества и недостатки MPP-систем по сравнению с ВС с общей памятью? 38. Охарактеризуйте направления NOW и PoPC в построении кластерных ВС. 39. Перечислите основные задачи управления вычислительными ресурсами в параллельных ВС. Откуда возникают эти задачи? 40. Что такое «скрытый параллелизм» задачи, и как он нивелируется в ВС традиционной архитектуры? 41. По каким принципам строятся ВС, управляемые потоком данных? 42. Сравните преимущества и недостатки традиционных и потоковых ВС. 43. Перечислите основные свойства и характеристики систолических массивов. 44. Что такое систолизация, и из каких этапов она состоит? |




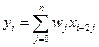 ,
,